
Download Lectures on Biostatistics (1971). Corrected and searchable version of Google books edition
Download review of Lectures on Biostatistics (THES, 1973).
|
“Statistical regression to the mean predicts that patients selected for abnormalcy will, on the average, tend to improve. We argue that most improvements attributed to the placebo effect are actually instances of statistical regression.”
“Thus, we urge caution in interpreting patient improvements as causal effects of our actions and should avoid the conceit of assuming that our personal presence has strong healing powers.” |
In 1955, Henry Beecher published "The Powerful Placebo". I was in my second undergraduate year when it appeared. And for many decades after that I took it literally, They looked at 15 studies and found that an average 35% of them got "satisfactory relief" when given a placebo. This number got embedded in pharmacological folk-lore. He also mentioned that the relief provided by placebo was greatest in patients who were most ill.
Consider the common experiment in which a new treatment is compared with a placebo, in a double-blind randomised controlled trial (RCT). It’s common to call the responses measured in the placebo group the placebo response. But that is very misleading, and here’s why.
The responses seen in the group of patients that are treated with placebo arise from two quite different processes. One is the genuine psychosomatic placebo effect. This effect gives genuine (though small) benefit to the patient. The other contribution comes from the get-better-anyway effect. This is a statistical artefact and it provides no benefit whatsoever to patients. There is now increasing evidence that the latter effect is much bigger than the former.
How can you distinguish between real placebo effects and get-better-anyway effect?
The only way to measure the size of genuine placebo effects is to compare in an RCT the effect of a dummy treatment with the effect of no treatment at all. Most trials don’t have a no-treatment arm, but enough do that estimates can be made. For example, a Cochrane review by Hróbjartsson & Gøtzsche (2010) looked at a wide variety of clinical conditions. Their conclusion was:
“We did not find that placebo interventions have important clinical effects in general. However, in certain settings placebo interventions can influence patient-reported outcomes, especially pain and nausea, though it is difficult to distinguish patient-reported effects of placebo from biased reporting.”
In some cases, the placebo effect is barely there at all. In a non-blind comparison of acupuncture and no acupuncture, the responses were essentially indistinguishable (despite what the authors and the journal said). See "Acupuncturists show that acupuncture doesn’t work, but conclude the opposite"
So the placebo effect, though a real phenomenon, seems to be quite small. In most cases it is so small that it would be barely perceptible to most patients. Most of the reason why so many people think that medicines work when they don’t isn’t a result of the placebo response, but it’s the result of a statistical artefact.
Regression to the mean is a potent source of deception
The get-better-anyway effect has a technical name, regression to the mean. It has been understood since Francis Galton described it in 1886 (see Senn, 2011 for the history). It is a statistical phenomenon, and it can be treated mathematically (see references, below). But when you think about it, it’s simply common sense.
You tend to go for treatment when your condition is bad, and when you are at your worst, then a bit later you’re likely to be better, The great biologist, Peter Medawar comments thus.
|
"If a person is (a) poorly, (b) receives treatment intended to make him better, and (c) gets better, then no power of reasoning known to medical science can convince him that it may not have been the treatment that restored his health"
(Medawar, P.B. (1969:19). The Art of the Soluble: Creativity and originality in science. Penguin Books: Harmondsworth). |
This is illustrated beautifully by measurements made by McGorry et al., (2001). Patients with low back pain recorded their pain (on a 10 point scale) every day for 5 months (they were allowed to take analgesics ad lib).
The results for four patients are shown in their Figure 2. On average they stay fairly constant over five months, but they fluctuate enormously, with different patterns for each patient. Painful episodes that last for 2 to 9 days are interspersed with periods of lower pain or none at all. It is very obvious that if these patients had gone for treatment at the peak of their pain, then a while later they would feel better, even if they were not actually treated. And if they had been treated, the treatment would have been declared a success, despite the fact that the patient derived no benefit whatsoever from it. This entirely artefactual benefit would be the biggest for the patients that fluctuate the most (e.g this in panels a and d of the Figure).
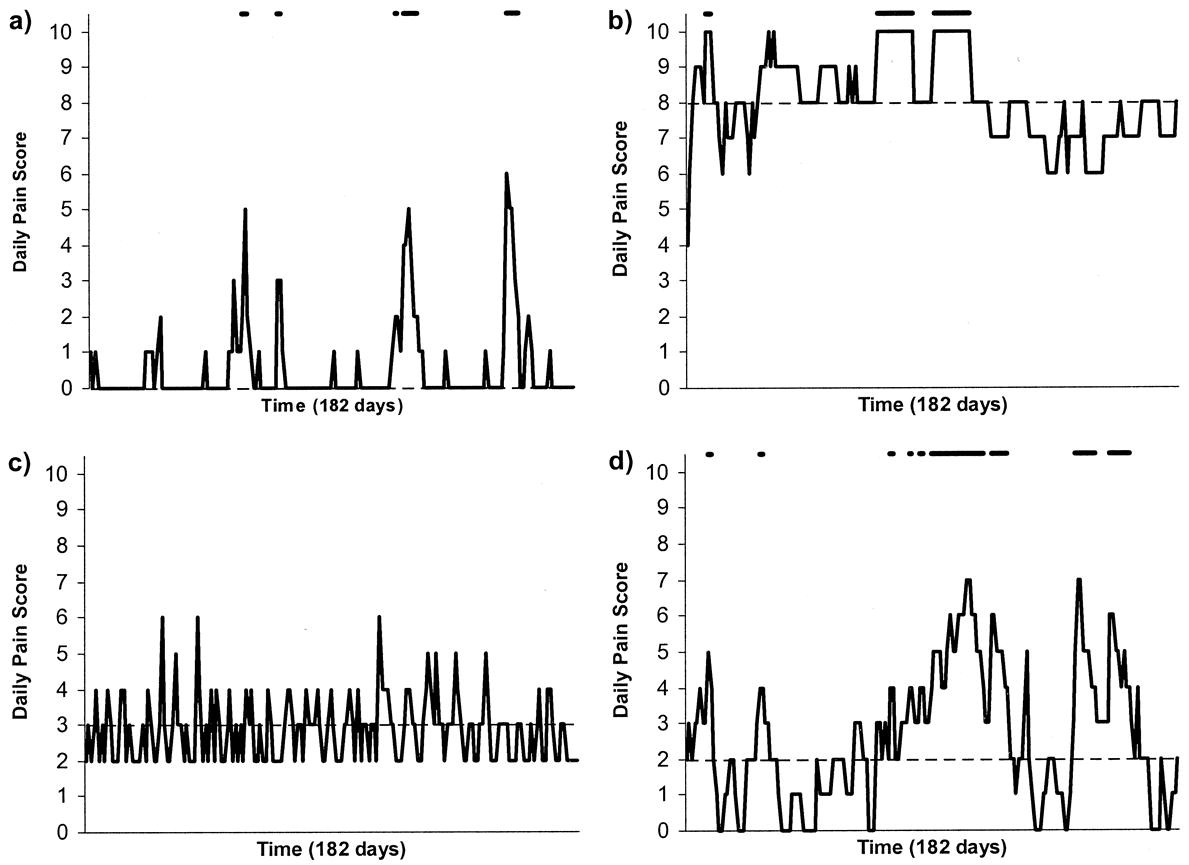
Figure 2 from McGorry et al, 2000. Examples of daily pain scores over a 6-month period for four participants. Note: Dashes of different lengths at the top of a figure designate an episode and its duration.
The effect is illustrated well by an analysis of 118 trials of treatments for non-specific low back pain (NSLBP), by Artus et al., (2010). The time course of pain (rated on a 100 point visual analogue pain scale) is shown in their Figure 2. There is a modest improvement in pain over a few weeks, but this happens regardless of what treatment is given, including no treatment whatsoever.
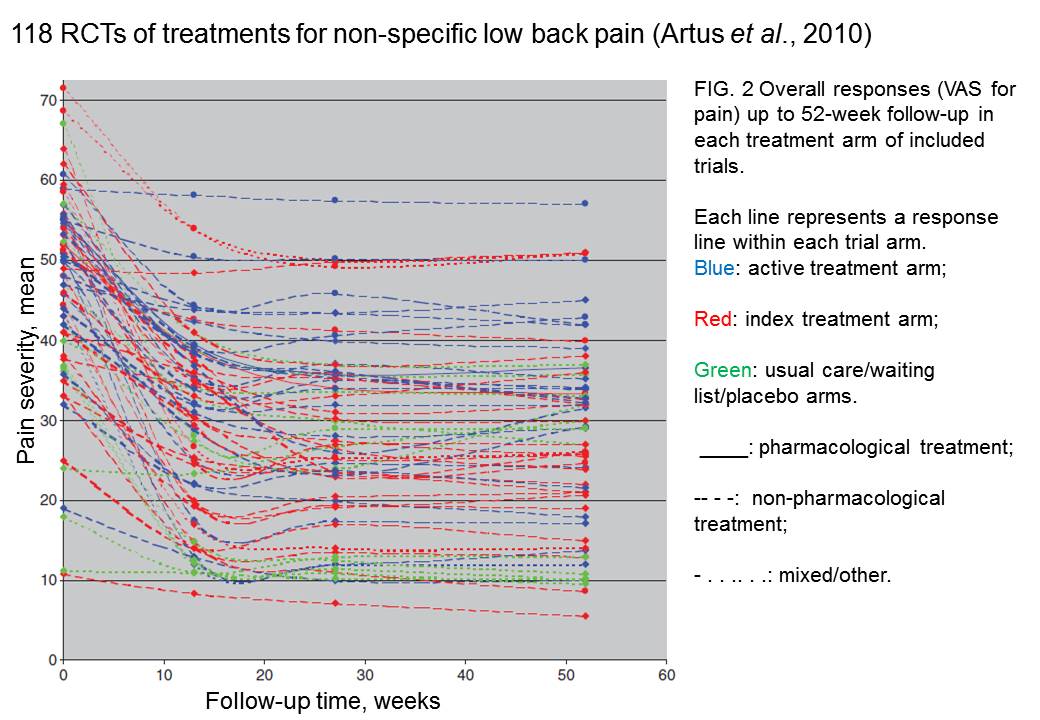
FIG. 2 Overall responses (VAS for pain) up to 52-week follow-up in each treatment arm of included trials. Each line represents a response line within each trial arm. Red: index treatment arm; Blue: active treatment arm; Green: usual care/waiting list/placebo arms. ____: pharmacological treatment; – – – -: non-pharmacological treatment; . . .. . .: mixed/other.
The authors comment
"symptoms seem to improve in a similar pattern in clinical trials following a wide variety of active as well as inactive treatments.", and "The common pattern of responses could, for a large part, be explained by the natural history of NSLBP".
In other words, none of the treatments work.
This paper was brought to my attention through the blog run by the excellent physiotherapist, Neil O’Connell. He comments
"If this finding is supported by future studies it might suggest that we can’t even claim victory through the non-specific effects of our interventions such as care, attention and placebo. People enrolled in trials for back pain may improve whatever you do. This is probably explained by the fact that patients enrol in a trial when their pain is at its worst which raises the murky spectre of regression to the mean and the beautiful phenomenon of natural recovery."
O’Connell has discussed the matter in recent paper, O’Connell (2015), from the point of view of manipulative therapies. That’s an area where there has been resistance to doing proper RCTs, with many people saying that it’s better to look at “real world” outcomes. This usually means that you look at how a patient changes after treatment. The hazards of this procedure are obvious from Artus et al.,Fig 2, above. It maximises the risk of being deceived by regression to the mean. As O’Connell commented
"Within-patient change in outcome might tell us how much an individual’s condition improved, but it does not tell us how much of this improvement was due to treatment."
In order to eliminate this effect it’s essential to do a proper RCT with control and treatment groups tested in parallel. When that’s done the control group shows the same regression to the mean as the treatment group. and any additional response in the latter can confidently attributed to the treatment. Anything short of that is whistling in the wind.
Needless to say, the suboptimal methods are most popular in areas where real effectiveness is small or non-existent. This, sad to say, includes low back pain. It also includes just about every treatment that comes under the heading of alternative medicine. Although these problems have been understood for over a century, it remains true that
|
"It is difficult to get a man to understand something, when his salary depends upon his not understanding it."
Upton Sinclair (1935) |
Responders and non-responders?
One excuse that’s commonly used when a treatment shows only a small effect in proper RCTs is to assert that the treatment actually has a good effect, but only in a subgroup of patients ("responders") while others don’t respond at all ("non-responders"). For example, this argument is often used in studies of anti-depressants and of manipulative therapies. And it’s universal in alternative medicine.
There’s a striking similarity between the narrative used by homeopaths and those who are struggling to treat depression. The pill may not work for many weeks. If the first sort of pill doesn’t work try another sort. You may get worse before you get better. One is reminded, inexorably, of Voltaire’s aphorism "The art of medicine consists in amusing the patient while nature cures the disease".
There is only a handful of cases in which a clear distinction can be made between responders and non-responders. Most often what’s observed is a smear of different responses to the same treatment -and the greater the variability, the greater is the chance of being deceived by regression to the mean.
For example, Thase et al., (2011) looked at responses to escitalopram, an SSRI antidepressant. They attempted to divide patients into responders and non-responders. An example (Fig 1a in their paper) is shown.
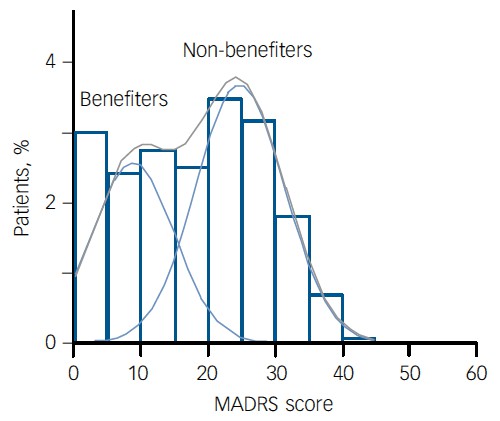
The evidence for such a bimodal distribution is certainly very far from obvious. The observations are just smeared out. Nonetheless, the authors conclude
"Our findings indicate that what appears to be a modest effect in the grouped data – on the boundary of clinical significance, as suggested above – is actually a very large effect for a subset of patients who benefited more from escitalopram than from placebo treatment. "
I guess that interpretation could be right, but it seems more likely to be a marketing tool. Before you read the paper, check the authors’ conflicts of interest.
The bottom line is that analyses that divide patients into responders and non-responders are reliable only if that can be done before the trial starts. Retrospective analyses are unreliable and unconvincing.
Some more reading
Senn, 2011 provides an excellent introduction (and some interesting history). The subtitle is
"Here Stephen Senn examines one of Galton’s most important statistical legacies – one that is at once so trivial that it is blindingly obvious, and so deep that many scientists spend their whole career being fooled by it."
The examples in this paper are extended in Senn (2009), “Three things that every medical writer should know about statistics”. The three things are regression to the mean, the error of the transposed conditional and individual response.
You can read slightly more technical accounts of regression to the mean in McDonald & Mazzuca (1983) "How much of the placebo effect is statistical regression" (two quotations from this paper opened this post), and in Stephen Senn (2015) "Mastering variation: variance components and personalised medicine". In 1988 Senn published some corrections to the maths in McDonald (1983).
The trials that were used by Hróbjartsson & Gøtzsche (2010) to investigate the comparison between placebo and no treatment were looked at again by Howick et al., (2013), who found that in many of them the difference between treatment and placebo was also small. Most of the treatments did not work very well.
Regression to the mean is not just a medical deceiver: it’s everywhere
Although this post has concentrated on deception in medicine, it’s worth noting that the phenomenon of regression to the mean can cause wrong inferences in almost any area where you look at change from baseline. A classical example concern concerns the effectiveness of speed cameras. They tend to be installed after a spate of accidents, and if the accident rate is particularly high in one year it is likely to be lower the next year, regardless of whether a camera had been installed or not. To find the true reduction in accidents caused by installation of speed cameras, you would need to choose several similar sites and allocate them at random to have a camera or no camera. As in clinical trials. looking at the change from baseline can be very deceptive.
Statistical postscript
Lastly, remember that it you avoid all of these hazards of interpretation, and your test of significance gives P = 0.047. that does not mean you have discovered something. There is still a risk of at least 30% that your ‘positive’ result is a false positive. This is explained in Colquhoun (2014),"An investigation of the false discovery rate and the misinterpretation of p-values". I’ve suggested that one way to solve this problem is to use different words to describe P values: something like this.
|
P > 0.05 very weak evidence
P = 0.05 weak evidence: worth another look P = 0.01 moderate evidence for a real effect P = 0.001 strong evidence for real effect |
But notice that if your hypothesis is implausible, even these criteria are too weak. For example, if the treatment and placebo are identical (as would be the case if the treatment were a homeopathic pill) then it follows that 100% of positive tests are false positives.
Follow-up
12 December 2015
It’s worth mentioning that the question of responders versus non-responders is closely-related to the classical topic of bioassays that use quantal responses. In that field it was assumed that each participant had an individual effective dose (IED). That’s reasonable for the old-fashioned LD50 toxicity test: every animal will die after a sufficiently big dose. It’s less obviously right for ED50 (effective dose in 50% of individuals). The distribution of IEDs is critical, but it has very rarely been determined. The cumulative form of this distribution is what determines the shape of the dose-response curve for fraction of responders as a function of dose. Linearisation of this curve, by means of the probit transformation used to be a staple of biological assay. This topic is discussed in Chapter 10 of Lectures on Biostatistics. And you can read some of the history on my blog about Some pharmacological history: an exam from 1959.

Fascinating. I have been arguing for 10 years that placebo effect can be useful and we need to understand it better, and you have turned that upside down. Well done.
@Majikthyse
The realisation that placebo effects are so small removes the last (very flimsy) plank from the arguments of those selling alternative medicine. And it’s also a blow for pharma companies who sell things that are near-ineffective.
Steve Novella has an interesting piece on the placebo effect (in which he includes regression to mean), including whether the placebo effect is getting stronger on his blog at Science Based Medicine
Recently, Medscape France ran a series of articles, which I didn’t read in detail because it isn’t my subject (see for example http://francais.medscape.com/voirarticle/3601836?nlid=90543_2401).
To summarise briefly, it’s been proposed that the placebo effect works when there exists an endogenous ligand for the drug (agonist or antagonist), such as a receptor. The right bedside manner sets things off. I read elsewhere that you can get a placebo effect even in patients who have been informed that that’s what they’re getting, as long as it’s done properly. A long time ago, former psychiatrist colleagues were convinced that lithium (for certain periodic disorders) and antidepressants are remarkably effective and are essential for success, but *only* if the doctor and other carers have a lot of time to spend with the patients.
All that may be too subtle for those who make the rules and regulations of clinical trials. Only this morning (perhaps it was yesterday) I heard on the wireless a discussion of the relative merits and costs (it *was* in the UK) of “talking” vs pharmacological treatment for depression, with great emphasis on the respective waiting lists. From my second-hand experience, the only thing reasonably sure to work is a combination of the two treatments, though it would be better to do without the traditional waiting lists.
@Christoper R Lee
I’m not doubting that genuine placebo responses exist, and can be measured in experiments that are designed to find them. But the empirical evidence suggests that they provide little or no benefit to real patients. That being the case, their possible mechanisms (endorphins etc) are not only speculative, but are also of little interest.
The main reason why people appear to respond to dummy pills (or to no treatment at all) is nothing to do with placebo responses: it is a statistical artefact. The principle has been understood for over 100 years, so it isn’t obvious to me why it isn’t better understood. I guess one reason is that understanding it may well reduce the income of both big pharma, and of the legions of quacks, who are eager to sell us things that don’t work.
I was a drug addict for many years in a country where good drugs were quite scarce. People were always trying to sell me placebos. It was obvious that they didn’t work, that there was a small measure of gullibility available for a short time with regard to extremely minor subjective phenomena but no real placebo effect.
I can think of another reason why placebo control arms need to be included in RCTs besides regression to the mean and any putative placebo effect.
Participants in trials are subjected to conditions that have real physiological effects. These include fasting for blood draws, the loss of blood in testing, white coat syndrome, even the response to meeting an attractive phlebotomist regularly. The idea that a particular type of behaviour is required of someone in an experiment could also produce significant effects (e.g. when testing a drug that interacts with alcohol, those on the placebo would be given the same advice about avoiding alcohol; but there is also likely to be a more general sense of responsibility among people in RCTs). Therefore, the closer the terms of the experiment are for the two arms, the better, and this includes taking phoney pills, if only as a marker of compliance. If the pills are to be taken with food (or not) at a certain time of day, this introduces another potential physiological modifier.
All these effects are likely to be minor, but may still be greater than any true placebo effect.
As a lay person, the one bit I don’t get is this:
“analyses that divide patients into responders and non-responders are reliable only if that can be done before the trial starts.”
How could you do that analysis in advance, without the data the trial will produce? Can you give a concrete example?
@ Stephen J
The idea is that some measurement that predicts responsiveness can be made before the trial.
A classical example is that it’s know that measurements of plasma cholinesterase predicts the response to the muscle relaxant, suxamethonium (the action of which is terminated by the cholinesterase enzyme).
The choice of whether or not to treat breast cancer with things like tamoxifen is based on measurements of the amount of oestrogen receptor, before treatment starts (eg see https://en.wikipedia.org/wiki/Breast_cancer_management ).
There has been a great deal of hype about personalised medicine, based on your DNA sequence (genome), though the complexities of genetics have meant that success, so far has been limited (eg see Caulfield, 2015). It’s coming, albeit more slowly that one hoped.
There are huge statistical problems in identifying non-responders after the trial. In particular, there is no guarantee that, if tested again, they would still be a non-responder. This is dealt with nicely in Senn (2009).
1. I understand how this shows that most reported placebo effects are not as strong as they seem, due to the fact that they do not account for the ‘get-better-anyway’ effect. However, I do not understand how this shows/quantifies the actual size of the ‘placebo’ effect and suggests that it is small?
2. The example given in Figure 2 regarding back pain states that “if these patients had gone for treatment at the peak of their pain, then a while later they would feel better” . Isn’t this effect also counterbalanced by the fact that regression to the mean occurs the other way. I.e. some individuals will also taken part in trials during a ‘trough’ and hence seem to get worse following treatment.
3. How can regression to the mean account for placebo effects in studies entirely composed of healthy controls. For example, I recall a pain thresholding experiment showing that participants given dummy placebo exhibit higher pain thresholds than individuals given nothing.
@mlab
(1) As I pointed out near the start, the best way to measure the real (useful) placebo effect is to compare groups who are given a placebo and groups who have no treatment at all. In most cases the difference is quite small, even when the comparison isn’t blind (so it can only overestimate the genuine placebo effect).
(2) Yes of course the effect can work in either direction. But not many people go for treatment when they are not suffering pain.
(3) There are lots of studies that show placebo effects under experimental conditions. I’m not doubting the reality of such results (though it’s always wise to check the effect size when looking at such studies). But empirically, these experimental results don’t seem to translate to real patients, with real pain
Excellent article as always!
Are you familiar with ANCOVA? One of the benefits of adjusting for baseline or pre-test values is to minimize the effect of regression to the mean effect. Here is an article from Altman and Vickers about using ANCOVA: Analysing controlled trials with baseline and follow up measurements
Also, subscribed to your youtube channel.!
@anoopbal
Thanks for your comment. It’s true that analysis of covariance (ANCOVA) is another way to make some allowance for regression to the mean. But it makes assumptions about linear relationship between response and time which may well not be justified. It’s better, in general, to have a parallel control group which should show the same regression to the mean as the test group. The paper that you mention (Vickers & Altman, 2001) inadvertently provides a rather good example. It looks at acupuncture, which was fashionable in 2001, but which is now well-established to be no more than a myth. Yet the ANCOVA analysis decreases the P value this giving the impression that it works for shoulder pain. A classical false positive.
Great post. Thank you.
Regarding:
“One excuse that’s commonly used when a treatment shows no effect, or a small effect, in proper RCTs is to assert that the treatment actually has a good effect, but only in a subgroup of patients (“responders”) while others don’t respond at all (“non-responders”).”
If the average treatment effect is zero then claiming that there is a subset for whom the treatment effect is positive also amounts to claiming that there is another subset for whom the treatment effect is negative (for whom the treatment is harmful). Without the latter the average effect could not be zero. The U.S. mathematical psychologist Robyn Dawes called not seeing this “the subset fallacy” in his book Everyday Irrationality (2001, ch.6).
On findings of subgroup differences in clinical trials, the U.S. biostatistician Curtis Meinert wrote:
“most subgroup differences identified by subgroup analyses have a nasty habit of not reproducing in subsequent trials” (An insider’s guide to clinical trials. Oxford, 2011, page 156)
In the same vein, Richard Peto has said that “you
should always do subgroup analysis and never believe the results”.
In other words, any finding from subgroup analysis needs to be confirmed in a separate medical trial. Otherwise, one is committing what is also known as the Texas sharpshooter fallacy: https://en.wikipedia.org/wiki/Texas_sharpshooter_fallacy
@Peter
Thanks for those excellent quotations.
Of course you are quite right about the zero effect. I’ve fixed that now. Thank you.
As I said, regression to the mean has been known for so long that it’s amazing that one still needs to write about it. The problem, I suppose, is that it is not in the interests of quacks to think about it. It’s also not in the interests of anyone who is being pressured to produce positive results.
As you point out, the hazards of post hoc subset analysis have also been known for a long time. The only safe rule is not to believe it until you can show that you have a method that will pick out responders before you give the treatment. That’s the aim of personalized medicine, but progress in that field has been rather slow, so far, as Tim Caulfield fas recently pointed out in the BMJ (“Genetics and personalized medicine—where’s the revolution?)
I find this post very compelling. How about the effects of meta-analyses on RCTs? I would suspect that meta-analyses would cover RCTs with from-each-other different “baseline-populations”, i.e, patients in individual RCTs are likely to start off from a specific baseline, however, it unlikely that a group of RCTs would start with patients with the same baseline. It would seem more probable that some RCTs would have “populations” starting from a high baseline, and some RCTs with a low baseline, and some RCTs with “median” baseline. That taken into account would diminsh the effects os “regression-to-the-mean”, would it not?
@beltea
Well RCTs are normally run with test and control groups in parallel, so, in principle both groups should experience the same regression to the mean, The problem arises largely in trials that look at difference from baseline. But of course it is a weakness of meta-analysis that you have to choose which trials to exclude.
*Placebo has nothing to do with ineffective pill taking but with the environment a therapy is administred. When judging placebo effects from RCT studies the danger arises that the intrinsic placebo (psychophysioloical effect) will be rather low because in many RCT studies the environmental effect is often targeted at minimising placebo. Indeed most medical companies who launch a new medication will have to compare it to placebo hence are strategically inclined to lower the placebo effect in order to make the statistical gap (they say “significance”) with their “effective” product as large as possible. I have seen studies where they even pre-select good placeboresponders and exclude them from the final study (selection bias). Therefore we must be cautious of this bias when judging placebo from RCT studies alone.
Dr. G. Otte
How can we explain what i use to denominate as the “placebo plus” effect. It was a study in Nature review neurosciences by Fabrizio Benedetti et al (http://www.nature.com/nrn/journal/v6/n7/full/nrn1705.html) where in an RCT study a supposed pain killer ( proglumide an cholecystokinine antagonist) was compared to placebo (same environmental context of administration) and gave a consistent statistical improvement over placebo. However when an assistant administered the product without knowledge of the patient , the proglumide did nothing at all. So here we are confronted with a product in itself totally inactive (hence placebo-like) that works better then placebo in strictly controlled RCT testing as long as the patient – and this is dubbel blind- is aware of it being adninistrated. I call it placebo plus and the article explains the causal effect.
Dr. G. Otte
@gotte
The study by Colloca and Benedetti (2005) [download pdf] was aware of regression to the mean (see Box 1) and it refers to an earlier version (Hróbjartsson & Gøtzsche, 2005) of the study to which I refer, namely Hróbjartsson & Gøtzsche (2010). It also acknowledges that the only way to distinguish between a genuine placebo effect and regression to the mean is to compare placebo with no-treatment. When this is done, it’s found that there is often (though not always) a difference, but that this difference, the genuine placebo effect) is too small to be useful to patients.
I don’t deny for a moment that real placebo effects exist, but in seems that, in real clinical settings, they usually aren’t big enough to be useful, and that the greatest part of difference between drug and placebo is accounted for be regression to the mean.
Colloca and Benedetti suggest that clinical trials should routinely include a comparison between open and covert administration of the drug. That would be interesting to placebo researchers, but it seems to me that it would be better to more often include a no-treatment arm. That would answer the important question in an ethically-acceptable way
*My favourite is in Danny Kahneman’s autobiography – the story about “regression to the mean explaining why rebukes can seem to improve performance, while praise seems to backfire” in the performance of Israeli flight instructors.
Sorry to be late to the party!
IMHO much of this discussion fails to distinguish what the ‘effects’ are, or are supposed to be.
Is the ‘work’ to which DC refers in the title of this thread ‘work’ on the body – ‘to have an effect on a specific disease, condition or ailment’ ?
If so, then (by definition) placebos have no effect greater than…placebos.
But if ‘ to help the patient come to terms with their condition, feel better about it, have a degree of hope, consolation, solace and charitable love’ – then many patients do indeed find the experience of being treated by a camist (one who uses CAMs) – beneficial. For them, ‘it works’.
Patients who decide to use camistry will have their response expectancies enhanced by the more theatrical placebos (to quote an eminent authority on such matters) – the pins, pushing, plants, pillules in a therapeutic environment with an apparently empathic practitioner all deepen the auto-hypnotic experience for these believers – and they go away ‘happy’. Up to a point, and for a time. As do those believers who go to church. It’s called TLC.
More in ‘Real Secrets of Alternative Medicine (Amazon)!
@Richard Rawlins.
I’m not denying that some people feel better after CAM treatment, but it seems that they main reason for that is that they’d have felt better even if they hadn’t had the treatment. The evidence that I cite suggests that the placebo, theatrical or otherwise, has quite small psychological effects. The quotation from Peter Medawar hits the nail on the head.
Of course that isn’t a reason to refrain from giving sick people some TLC while nature takes its course.
I think this is really interesting, but I would be extremely careful how I worded it.
If one discounts placebo as unimportant, then there’s a natural inclination to accept RCTs that ignore placebo (and blinding as well). I mean, if no-treatment arms are good enough, we can save a lot of money! We can look at a lot more treatments! Look at all these treatments we ignored because we compared them to placebo instead of to no-treatment!
The problem is that even though the effect of placebo as compared to RTM is small, so is the effect of treatment to RTM. If we let ourselves discount placebo, if we stop caring deeply about the controls we choose, we’re going to be making a lot of mistakes. (In your phrasing, which I appreciate, we’re going to be making fools of ourselves an awful lot of the time.)
If we aren’t extremely rigorous with this, we’ll end up discounting placebo entirely. Would Moseley’s famous paper ever be published in this environment? Or would we still be operating and failing to beat placebo?
To be sure, I don’t think that placebo is going to do anything for objective measures of something like renal failure. But we have to keep in mind that even when we treat objective measures, we are doing so in service to subjective measures. We don’t treat disease because disease is inherently bad; we treat it because it causes pain, fatigue, unhappiness. Even when we’re trying to save life or limb, we’re doing so according to our patients’ wishes, wishes made without consciousness of lab values or imaging, made with consciousness only of unquantifiable pain, fear, and hope. With this understanding, it’s clear that the effect of placebo on objective measures is irrelevant. All of our objective measures are merely proxies for future, subjective measures.
@vasiln
Oh no, I think that you’re quite wrong to say
The point of having a control group is that regression to the mean will distort the results to the same extent (on average) in the control and intervention groups.
@David Colquhoun
If you discount placebo as too small to worry about, you still need a control group to assess regression to the mean, but that control group need not be treated with placebo. A no-treatment control can measure regression to the mean as well as a placebo control.
@vasiln
As explained at the start of this post, treatment vs placebo measures placebo effect + regression to the mean. To measure the genuine placebo effect you have to compare placebo vs no-treatment.
Yes. Exactly. I’m sorry that I’m not expressing my point clearly.
If you compare no-treatment to placebo arms and come to the conclusion that there is no difference– that is, that the entirety is regression to the mean– then it would irresponsible to waste resources on a placebo control when a much cheaper no-treatment control would measure the exact same thing.
Note that Hrobjartsson and Gotzsche do not come to the conclusion that placebo is mythical, but it is not difficult to find people who have (and frequently cite H&G.)
@Vaslin
Neither I, nor Hróbjartsson & Gøtzsche (2010), said that placebo effects are non-existent: quite on the contrary. We said merely that, on average, they are too small to give noticeable relief to patients. That doesn’t mean that they can be ignored in a properly-conducted trial.
Regarding your “Statistical postscript”: In my understanding, it is a misinterpretation to use p-values like you do: as a measure of strength of evidence.
As far as I know, for such claims you need Bayesian stats; that also lets you take into account the prior plausibility of the effect.
@Ondrej Havlicek
If you had followed the link in the statistical postscript, you would have seen that that’s exactly what I said.
I’ve recent;y posted a sequel paper, The Reproducibility Of Research And The Misinterpretation Of P Values, which deals with these questions in greater detail. I also propose some solutions, e.g. to cite minimum false positive rates, and to use the reverse Bayesian argument to give the prior thqt would be needed to produce an acceptable false positive rate.
One thing which seems to be missing from this discussion is the ability to help people. It seems to me (and I would love to be corrected / pointed in the right direction) that these studies try to narrow down the definition of placebo as much as possible so that they can show “you see, placebo does not work”.
However, even in the following situations:
– patient is ill, patient gets better (due to “regression to the mean”)
– patient is ill, patient gets placebo and gets better (due to “regression to the mean”)
I still argue that there is a value to administering the placebo – it gives much more tangible hope to the patient than just saying “you’ll get better” and reduces their anxiety. I would love to see some studies which look at this.
Again, I’m just worried that we’re loosing sight of the mission (helping people) just because we want to be “perfectly rational”.