
Download Lectures on Biostatistics (1971). Corrected and searchable version of Google books edition
Download review of Lectures on Biostatistics (THES, 1973).
publishing
|
“Statistical regression to the mean predicts that patients selected for abnormalcy will, on the average, tend to improve. We argue that most improvements attributed to the placebo effect are actually instances of statistical regression.”
“Thus, we urge caution in interpreting patient improvements as causal effects of our actions and should avoid the conceit of assuming that our personal presence has strong healing powers.” |
In 1955, Henry Beecher published "The Powerful Placebo". I was in my second undergraduate year when it appeared. And for many decades after that I took it literally, They looked at 15 studies and found that an average 35% of them got "satisfactory relief" when given a placebo. This number got embedded in pharmacological folk-lore. He also mentioned that the relief provided by placebo was greatest in patients who were most ill.
Consider the common experiment in which a new treatment is compared with a placebo, in a double-blind randomised controlled trial (RCT). It’s common to call the responses measured in the placebo group the placebo response. But that is very misleading, and here’s why.
The responses seen in the group of patients that are treated with placebo arise from two quite different processes. One is the genuine psychosomatic placebo effect. This effect gives genuine (though small) benefit to the patient. The other contribution comes from the get-better-anyway effect. This is a statistical artefact and it provides no benefit whatsoever to patients. There is now increasing evidence that the latter effect is much bigger than the former.
How can you distinguish between real placebo effects and get-better-anyway effect?
The only way to measure the size of genuine placebo effects is to compare in an RCT the effect of a dummy treatment with the effect of no treatment at all. Most trials don’t have a no-treatment arm, but enough do that estimates can be made. For example, a Cochrane review by Hróbjartsson & Gøtzsche (2010) looked at a wide variety of clinical conditions. Their conclusion was:
“We did not find that placebo interventions have important clinical effects in general. However, in certain settings placebo interventions can influence patient-reported outcomes, especially pain and nausea, though it is difficult to distinguish patient-reported effects of placebo from biased reporting.”
In some cases, the placebo effect is barely there at all. In a non-blind comparison of acupuncture and no acupuncture, the responses were essentially indistinguishable (despite what the authors and the journal said). See "Acupuncturists show that acupuncture doesn’t work, but conclude the opposite"
So the placebo effect, though a real phenomenon, seems to be quite small. In most cases it is so small that it would be barely perceptible to most patients. Most of the reason why so many people think that medicines work when they don’t isn’t a result of the placebo response, but it’s the result of a statistical artefact.
Regression to the mean is a potent source of deception
The get-better-anyway effect has a technical name, regression to the mean. It has been understood since Francis Galton described it in 1886 (see Senn, 2011 for the history). It is a statistical phenomenon, and it can be treated mathematically (see references, below). But when you think about it, it’s simply common sense.
You tend to go for treatment when your condition is bad, and when you are at your worst, then a bit later you’re likely to be better, The great biologist, Peter Medawar comments thus.
|
"If a person is (a) poorly, (b) receives treatment intended to make him better, and (c) gets better, then no power of reasoning known to medical science can convince him that it may not have been the treatment that restored his health"
(Medawar, P.B. (1969:19). The Art of the Soluble: Creativity and originality in science. Penguin Books: Harmondsworth). |
This is illustrated beautifully by measurements made by McGorry et al., (2001). Patients with low back pain recorded their pain (on a 10 point scale) every day for 5 months (they were allowed to take analgesics ad lib).
The results for four patients are shown in their Figure 2. On average they stay fairly constant over five months, but they fluctuate enormously, with different patterns for each patient. Painful episodes that last for 2 to 9 days are interspersed with periods of lower pain or none at all. It is very obvious that if these patients had gone for treatment at the peak of their pain, then a while later they would feel better, even if they were not actually treated. And if they had been treated, the treatment would have been declared a success, despite the fact that the patient derived no benefit whatsoever from it. This entirely artefactual benefit would be the biggest for the patients that fluctuate the most (e.g this in panels a and d of the Figure).
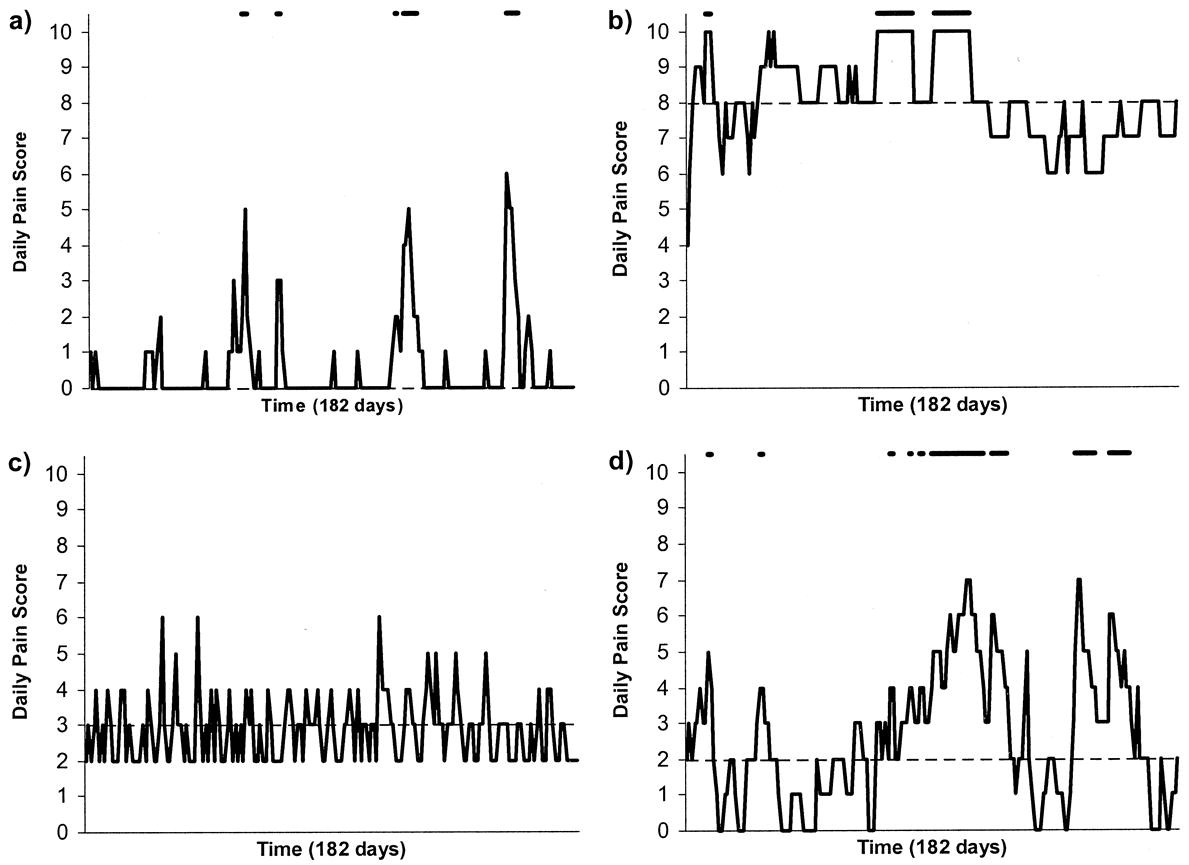
Figure 2 from McGorry et al, 2000. Examples of daily pain scores over a 6-month period for four participants. Note: Dashes of different lengths at the top of a figure designate an episode and its duration.
The effect is illustrated well by an analysis of 118 trials of treatments for non-specific low back pain (NSLBP), by Artus et al., (2010). The time course of pain (rated on a 100 point visual analogue pain scale) is shown in their Figure 2. There is a modest improvement in pain over a few weeks, but this happens regardless of what treatment is given, including no treatment whatsoever.
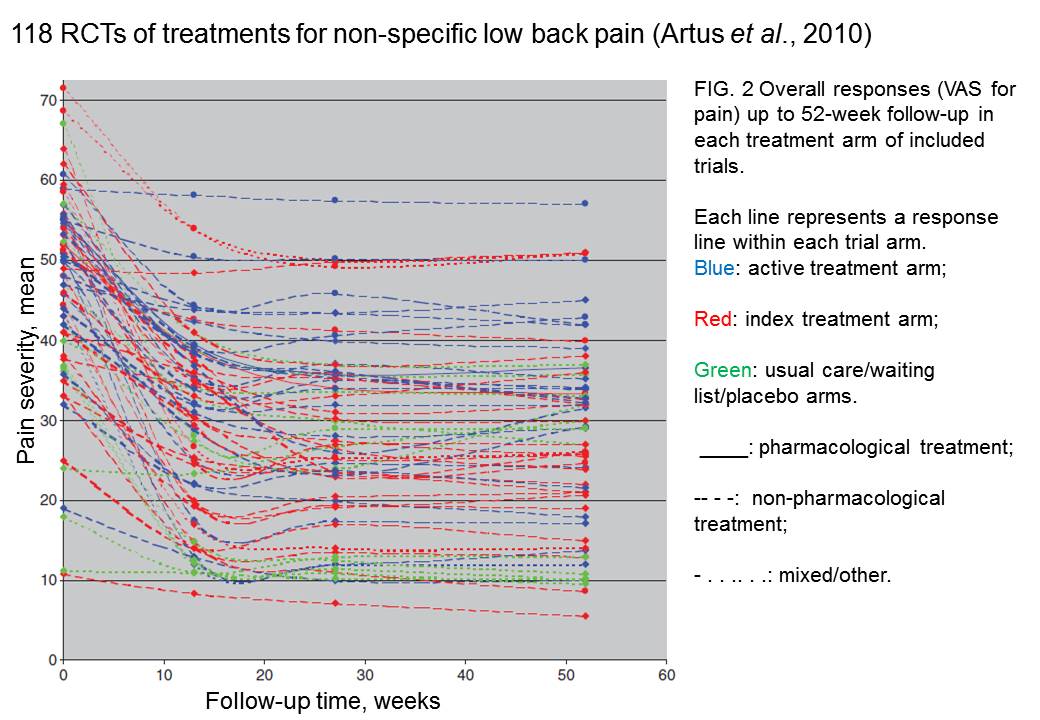
FIG. 2 Overall responses (VAS for pain) up to 52-week follow-up in each treatment arm of included trials. Each line represents a response line within each trial arm. Red: index treatment arm; Blue: active treatment arm; Green: usual care/waiting list/placebo arms. ____: pharmacological treatment; – – – -: non-pharmacological treatment; . . .. . .: mixed/other.
The authors comment
"symptoms seem to improve in a similar pattern in clinical trials following a wide variety of active as well as inactive treatments.", and "The common pattern of responses could, for a large part, be explained by the natural history of NSLBP".
In other words, none of the treatments work.
This paper was brought to my attention through the blog run by the excellent physiotherapist, Neil O’Connell. He comments
"If this finding is supported by future studies it might suggest that we can’t even claim victory through the non-specific effects of our interventions such as care, attention and placebo. People enrolled in trials for back pain may improve whatever you do. This is probably explained by the fact that patients enrol in a trial when their pain is at its worst which raises the murky spectre of regression to the mean and the beautiful phenomenon of natural recovery."
O’Connell has discussed the matter in recent paper, O’Connell (2015), from the point of view of manipulative therapies. That’s an area where there has been resistance to doing proper RCTs, with many people saying that it’s better to look at “real world” outcomes. This usually means that you look at how a patient changes after treatment. The hazards of this procedure are obvious from Artus et al.,Fig 2, above. It maximises the risk of being deceived by regression to the mean. As O’Connell commented
"Within-patient change in outcome might tell us how much an individual’s condition improved, but it does not tell us how much of this improvement was due to treatment."
In order to eliminate this effect it’s essential to do a proper RCT with control and treatment groups tested in parallel. When that’s done the control group shows the same regression to the mean as the treatment group. and any additional response in the latter can confidently attributed to the treatment. Anything short of that is whistling in the wind.
Needless to say, the suboptimal methods are most popular in areas where real effectiveness is small or non-existent. This, sad to say, includes low back pain. It also includes just about every treatment that comes under the heading of alternative medicine. Although these problems have been understood for over a century, it remains true that
|
"It is difficult to get a man to understand something, when his salary depends upon his not understanding it."
Upton Sinclair (1935) |
Responders and non-responders?
One excuse that’s commonly used when a treatment shows only a small effect in proper RCTs is to assert that the treatment actually has a good effect, but only in a subgroup of patients ("responders") while others don’t respond at all ("non-responders"). For example, this argument is often used in studies of anti-depressants and of manipulative therapies. And it’s universal in alternative medicine.
There’s a striking similarity between the narrative used by homeopaths and those who are struggling to treat depression. The pill may not work for many weeks. If the first sort of pill doesn’t work try another sort. You may get worse before you get better. One is reminded, inexorably, of Voltaire’s aphorism "The art of medicine consists in amusing the patient while nature cures the disease".
There is only a handful of cases in which a clear distinction can be made between responders and non-responders. Most often what’s observed is a smear of different responses to the same treatment -and the greater the variability, the greater is the chance of being deceived by regression to the mean.
For example, Thase et al., (2011) looked at responses to escitalopram, an SSRI antidepressant. They attempted to divide patients into responders and non-responders. An example (Fig 1a in their paper) is shown.
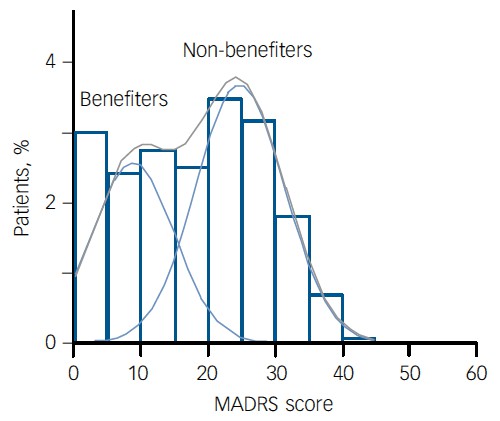
The evidence for such a bimodal distribution is certainly very far from obvious. The observations are just smeared out. Nonetheless, the authors conclude
"Our findings indicate that what appears to be a modest effect in the grouped data – on the boundary of clinical significance, as suggested above – is actually a very large effect for a subset of patients who benefited more from escitalopram than from placebo treatment. "
I guess that interpretation could be right, but it seems more likely to be a marketing tool. Before you read the paper, check the authors’ conflicts of interest.
The bottom line is that analyses that divide patients into responders and non-responders are reliable only if that can be done before the trial starts. Retrospective analyses are unreliable and unconvincing.
Some more reading
Senn, 2011 provides an excellent introduction (and some interesting history). The subtitle is
"Here Stephen Senn examines one of Galton’s most important statistical legacies – one that is at once so trivial that it is blindingly obvious, and so deep that many scientists spend their whole career being fooled by it."
The examples in this paper are extended in Senn (2009), “Three things that every medical writer should know about statistics”. The three things are regression to the mean, the error of the transposed conditional and individual response.
You can read slightly more technical accounts of regression to the mean in McDonald & Mazzuca (1983) "How much of the placebo effect is statistical regression" (two quotations from this paper opened this post), and in Stephen Senn (2015) "Mastering variation: variance components and personalised medicine". In 1988 Senn published some corrections to the maths in McDonald (1983).
The trials that were used by Hróbjartsson & Gøtzsche (2010) to investigate the comparison between placebo and no treatment were looked at again by Howick et al., (2013), who found that in many of them the difference between treatment and placebo was also small. Most of the treatments did not work very well.
Regression to the mean is not just a medical deceiver: it’s everywhere
Although this post has concentrated on deception in medicine, it’s worth noting that the phenomenon of regression to the mean can cause wrong inferences in almost any area where you look at change from baseline. A classical example concern concerns the effectiveness of speed cameras. They tend to be installed after a spate of accidents, and if the accident rate is particularly high in one year it is likely to be lower the next year, regardless of whether a camera had been installed or not. To find the true reduction in accidents caused by installation of speed cameras, you would need to choose several similar sites and allocate them at random to have a camera or no camera. As in clinical trials. looking at the change from baseline can be very deceptive.
Statistical postscript
Lastly, remember that it you avoid all of these hazards of interpretation, and your test of significance gives P = 0.047. that does not mean you have discovered something. There is still a risk of at least 30% that your ‘positive’ result is a false positive. This is explained in Colquhoun (2014),"An investigation of the false discovery rate and the misinterpretation of p-values". I’ve suggested that one way to solve this problem is to use different words to describe P values: something like this.
|
P > 0.05 very weak evidence
P = 0.05 weak evidence: worth another look P = 0.01 moderate evidence for a real effect P = 0.001 strong evidence for real effect |
But notice that if your hypothesis is implausible, even these criteria are too weak. For example, if the treatment and placebo are identical (as would be the case if the treatment were a homeopathic pill) then it follows that 100% of positive tests are false positives.
Follow-up
12 December 2015
It’s worth mentioning that the question of responders versus non-responders is closely-related to the classical topic of bioassays that use quantal responses. In that field it was assumed that each participant had an individual effective dose (IED). That’s reasonable for the old-fashioned LD50 toxicity test: every animal will die after a sufficiently big dose. It’s less obviously right for ED50 (effective dose in 50% of individuals). The distribution of IEDs is critical, but it has very rarely been determined. The cumulative form of this distribution is what determines the shape of the dose-response curve for fraction of responders as a function of dose. Linearisation of this curve, by means of the probit transformation used to be a staple of biological assay. This topic is discussed in Chapter 10 of Lectures on Biostatistics. And you can read some of the history on my blog about Some pharmacological history: an exam from 1959.
In the course of thinking about metrics, I keep coming across cases of over-promoted research. An early case was “Why honey isn’t a wonder cough cure: more academic spin“. More recently, I noticed these examples.
“Effect of Vitamin E and Memantine on Functional Decline in Alzheimer Disease".(Spoiler -very little), published in the Journal of the American Medical Association. ”
and ” Primary Prevention of Cardiovascular Disease with a Mediterranean Diet” , in the New England Journal of Medicine (which had second highest altmetric score in 2013)
and "Sleep Drives Metabolite Clearance from the Adult Brain", published in Science
In all these cases, misleading press releases were issued by the journals themselves and by the universities. These were copied out by hard-pressed journalists and made headlines that were certainly not merited by the work. In the last three cases, hyped up tweets came from the journals. The responsibility for this hype must eventually rest with the authors. The last two papers came second and fourth in the list of highest altmetric scores for 2013
Here are to two more very recent examples. It seems that every time I check a highly tweeted paper, it turns out that it is very second rate. Both papers involve fMRI imaging, and since the infamous dead salmon paper, I’ve been a bit sceptical about them. But that is irrelevant to what follows.
Boost your memory with electricity
That was a popular headline at the end of August. It referred to a paper in Science magazine:
“Targeted enhancement of cortical-hippocampal brain networks and associative memory” (Wang, JX et al, Science, 29 August, 2014)
This study was promoted by the Northwestern University "Electric current to brain boosts memory". And Science tweeted along the same lines.

|
Science‘s link did not lead to the paper, but rather to a puff piece, "Rebooting memory with magnets". Again all the emphasis was on memory, with the usual entirely speculative stuff about helping Alzheimer’s disease. But the paper itself was behind Science‘s paywall. You couldn’t read it unless your employer subscribed to Science.
|
 |
|
All the publicity led to much retweeting and a big altmetrics score. Given that the paper was not open access, it’s likely that most of the retweeters had not actually read the paper. |
|
When you read the paper, you found that is mostly not about memory at all. It was mostly about fMRI. In fact the only reference to memory was in a subsection of Figure 4. This is the evidence.
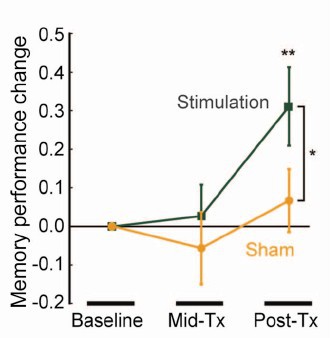
That looks desperately unconvincing to me. The test of significance gives P = 0.043. In an underpowered study like this, the chance of this being a false discovery is probably at least 50%. A result like this means, at most, "worth another look". It does not begin to justify all the hype that surrounded the paper. The journal, the university’s PR department, and ultimately the authors, must bear the responsibility for the unjustified claims.
Science does not allow online comments following the paper, but there are now plenty of sites that do. NHS Choices did a fairly good job of putting the paper into perspective, though they failed to notice the statistical weakness. A commenter on PubPeer noted that Science had recently announced that it would tighten statistical standards. In this case, they failed. The age of post-publication peer review is already reaching maturity
Boost your memory with cocoa
Another glamour journal, Nature Neuroscience, hit the headlines on October 26, 2014, in a paper that was publicised in a Nature podcast and a rather uninformative press release.
"Enhancing dentate gyrus function with dietary flavanols improves cognition in older adults. Brickman et al., Nat Neurosci. 2014. doi: 10.1038/nn.3850.".
The journal helpfully lists no fewer that 89 news items related to this study. Mostly they were something like “Drinking cocoa could improve your memory” (Kat Lay, in The Times). Only a handful of the 89 reports spotted the many problems.
A puff piece from Columbia University’s PR department quoted the senior author, Dr Small, making the dramatic claim that
“If a participant had the memory of a typical 60-year-old at the beginning of the study, after three months that person on average had the memory of a typical 30- or 40-year-old.”
|
Like anything to do with diet, the paper immediately got circulated on Twitter. No doubt most of the people who retweeted the message had not read the (paywalled) paper. The links almost all led to inaccurate press accounts, not to the paper itself. |
|
But some people actually read the paywalled paper and post-publication review soon kicked in. Pubmed Commons is a good site for that, because Pubmed is where a lot of people go for references. Hilda Bastian kicked off the comments there (her comment was picked out by Retraction Watch). Her conclusion was this.
"It’s good to see claims about dietary supplements tested. However, the results here rely on a chain of yet-to-be-validated assumptions that are still weakly supported at each point. In my opinion, the immodest title of this paper is not supported by its contents."
(Hilda Bastian runs the Statistically Funny blog -“The comedic possibilities of clinical epidemiology are known to be limitless”, and also a Scientific American blog about risk, Absolutely Maybe.)
NHS Choices spotted most of the problems too, in "A mug of cocoa is not a cure for memory problems". And so did Ian Musgrave of the University of Adelaide who wrote "Most Disappointing Headline Ever (No, Chocolate Will Not Improve Your Memory)",
Here are some of the many problems.
- The paper was not about cocoa. Drinks containing 900 mg cocoa flavanols (as much as in about 25 chocolate bars) and 138 mg of (−)-epicatechin were compared with much lower amounts of these compounds
- The abstract, all that most people could read, said that subjects were given "high or low cocoa–containing diet for 3 months". Bit it wasn’t a test of cocoa: it was a test of a dietary "supplement".
- The sample was small (37ppeople altogether, split between four groups), and therefore under-powered for detection of the small effect that was expected (and observed)
- The authors declared the result to be "significant" but you had to hunt through the paper to discover that this meant P = 0.04 (hint -it’s 6 lines above Table 1). That means that there is around a 50% chance that it’s a false discovery.
- The test was short -only three months
- The test didn’t measure memory anyway. It measured reaction speed, They did test memory retention too, and there was no detectable improvement. This was not mentioned in the abstract, Neither was the fact that exercise had no detectable effect.
- The study was funded by the Mars bar company. They, like many others, are clearly looking for a niche in the huge "supplement" market,
The claims by the senior author, in a Columbia promotional video that the drink produced "an improvement in memory" and "an improvement in memory performance by two or three decades" seem to have a very thin basis indeed. As has the statement that "we don’t need a pharmaceutical agent" to ameliorate a natural process (aging). High doses of supplements are pharmaceutical agents.
To be fair, the senior author did say, in the Columbia press release, that "the findings need to be replicated in a larger study—which he and his team plan to do". But there is no hint of this in the paper itself, or in the title of the press release "Dietary Flavanols Reverse Age-Related Memory Decline". The time for all the publicity is surely after a well-powered study, not before it.
The high altmetrics score for this paper is yet another blow to the reputation of altmetrics.
One may well ask why Nature Neuroscience and the Columbia press office allowed such extravagant claims to be made on such a flimsy basis.
What’s going wrong?
These two papers have much in common. Elaborate imaging studies are accompanied by poor functional tests. All the hype focusses on the latter. These led me to the speculation ( In Pubmed Commons) that what actually happens is as follows.
- Authors do big imaging (fMRI) study.
- Glamour journal says coloured blobs are no longer enough and refuses to publish without functional information.
- Authors tag on a small human study.
- Paper gets published.
- Hyped up press releases issued that refer mostly to the add on.
- Journal and authors are happy.
- But science is not advanced.
It’s no wonder that Dorothy Bishop wrote "High-impact journals: where newsworthiness trumps methodology".
It’s time we forgot glamour journals. Publish open access on the web with open comments. Post-publication peer review is working
But boycott commercial publishers who charge large amounts for open access. It shouldn’t cost more than about £200, and more and more are essentially free (my latest will appear shortly in Royal Society Open Science).
Follow-up
Hilda Bastian has an excellent post about the dangers of reading only the abstract "Science in the Abstract: Don’t Judge a Study by its Cover"
4 November 2014
I was upbraided on Twitter by Euan Adie, founder of Almetric.com, because I didn’t click through the altmetric symbol to look at the citations "shouldn’t have to tell you to look at the underlying data David" and "you could have saved a lot of Google time". But when I did do that, all I found was a list of media reports and blogs -pretty much the same as Nature Neuroscience provides itself.
More interesting, I found that my blog wasn’t listed and neither was PubMed Commons. When I asked why, I was told "needs to regularly cite primary research. PubMed, PMC or repository links”. But this paper is behind a paywall. So I provide (possibly illegally) a copy of it, so anyone can verify my comments. The result is that altmetric’s dumb algorithms ignore it. In order to get counted you have to provide links that lead nowhere.
So here’s a link to the abstract (only) in Pubmed for the Science paper http://www.ncbi.nlm.nih.gov/pubmed/25170153 and here’s the link for the Nature Neuroscience paper http://www.ncbi.nlm.nih.gov/pubmed/25344629
It seems that altmetrics doesn’t even do the job that it claims to do very efficiently.
It worked. By later in the day, this blog was listed in both Nature‘s metrics section and by altmetrics. com. But comments on Pubmed Commons were still missing, That’s bad because it’s an excellent place for post-publications peer review.
This discussion seemed to be of sufficient general interest that we submitted is as a feature to eLife, because this journal is one of the best steps into the future of scientific publishing. Sadly the features editor thought that " too much of the article is taken up with detailed criticisms of research papers from NEJM and Science that appeared in the altmetrics top 100 for 2013; while many of these criticisms seems valid, the Features section of eLife is not the venue where they should be published". That’s pretty typical of what most journals would say. It is that sort of attitude that stifles criticism, and that is part of the problem. We should be encouraging post-publication peer review, not suppressing it. Luckily, thanks to the web, we are now much less constrained by journal editors than we used to be.
Here it is.
Scientists don’t count: why you should ignore altmetrics and other bibliometric nightmares
David Colquhoun1 and Andrew Plested2
1 University College London, Gower Street, London WC1E 6BT
2 Leibniz-Institut für Molekulare Pharmakologie (FMP) & Cluster of Excellence NeuroCure, Charité Universitätsmedizin,Timoféeff-Ressowsky-Haus, Robert-Rössle-Str. 10, 13125 Berlin Germany.
Jeffrey Beall is librarian at Auraria Library, University of Colorado Denver. Although not a scientist himself, he, more than anyone, has done science a great service by listing the predatory journals that have sprung up in the wake of pressure for open access. In August 2012 he published “Article-Level Metrics: An Ill-Conceived and Meretricious Idea. At first reading that criticism seemed a bit strong. On mature consideration, it understates the potential that bibliometrics, altmetrics especially, have to undermine both science and scientists.
Altmetrics is the latest buzzword in the vocabulary of bibliometricians. It attempts to measure the “impact” of a piece of research by counting the number of times that it’s mentioned in tweets, Facebook pages, blogs, YouTube and news media. That sounds childish, and it is. Twitter is an excellent tool for journalism. It’s good for debunking bad science, and for spreading links, but too brief for serious discussions. It’s rarely useful for real science.
Surveys suggest that the great majority of scientists do not use twitter (7 — 13%). Scientific works get tweeted about mostly because they have titles that contain buzzwords, not because they represent great science.
What and who is Altmetrics for?
The aims of altmetrics are ambiguous to the point of dishonesty; they depend on whether the salesperson is talking to a scientist or to a potential buyer of their wares.
At a meeting in London , an employee of altmetric.com said “we measure online attention surrounding journal articles” “we are not measuring quality …” “this whole altmetrics data service was born as a service for publishers”, “it doesn’t matter if you got 1000 tweets . . .all you need is one blog post that indicates that someone got some value from that paper”.
These ideas sound fairly harmless, but in stark contrast, Jason Priem (an author of the altmetrics manifesto) said one advantage of altmetrics is that it’s fast “Speed: months or weeks, not years: faster evaluations for tenure/hiring”. Although conceivably useful for disseminating preliminary results, such speed isn’t important for serious science (the kind that ought to be considered for tenure) which operates on the timescale of years. Priem also says “researchers must ask if altmetrics really reflect impact” . Even he doesn’t know, yet altmetrics services are being sold to universities, before any evaluation of their usefulness has been done, and universities are buying them. The idea that altmetrics scores could be used for hiring is nothing short of terrifying.
The problem with bibliometrics
The mistake made by all bibliometricians is that they fail to consider the content of papers, because they have no desire to understand research. Bibliometrics are for people who aren’t prepared to take the time (or lack the mental capacity) to evaluate research by reading about it, or in the case of software or databases, by using them. The use of surrogate outcomes in clinical trials is rightly condemned. Bibliometrics are all about surrogate outcomes.
If instead we consider the work described in particular papers that most people agree to be important (or that everyone agrees to be bad), it’s immediately obvious that no publication metrics can measure quality. There are some examples in How to get good science (Colquhoun, 2007). It is shown there that at least one Nobel prize winner failed dismally to fulfil arbitrary biblometric productivity criteria of the sort imposed in some universities (another example is in Is Queen Mary University of London trying to commit scientific suicide?).
Schekman (2013) has said that science
“is disfigured by inappropriate incentives. The prevailing structures of personal reputation and career advancement mean the biggest rewards often follow the flashiest work, not the best.”
Bibliometrics reinforce those inappropriate incentives. A few examples will show that altmetrics are one of the silliest metrics so far proposed.
The altmetrics top 100 for 2103
The superficiality of altmetrics is demonstrated beautifully by the list of the 100 papers with the highest altmetric scores in 2013 For a start, 58 of the 100 were behind paywalls, and so unlikely to have been read except (perhaps) by academics.
The second most popular paper (with the enormous altmetric score of 2230) was published in the New England Journal of Medicine. The title was Primary Prevention of Cardiovascular Disease with a Mediterranean Diet. It was promoted (inaccurately) by the journal with the following tweet:

Many of the 2092 tweets related to this article simply gave the title, but inevitably the theme appealed to diet faddists, with plenty of tweets like the following:


The interpretations of the paper promoted by these tweets were mostly desperately inaccurate. Diet studies are anyway notoriously unreliable. As John Ioannidis has said
"Almost every single nutrient imaginable has peer reviewed publications associating it with almost any outcome."
This sad situation comes about partly because most of the data comes from non-randomised cohort studies that tell you nothing about causality, and also because the effects of diet on health seem to be quite small.
The study in question was a randomized controlled trial, so it should be free of the problems of cohort studies. But very few tweeters showed any sign of having read the paper. When you read it you find that the story isn’t so simple. Many of the problems are pointed out in the online comments that follow the paper. Post-publication peer review really can work, but you have to read the paper. The conclusions are pretty conclusively demolished in the comments, such as:
“I’m surrounded by olive groves here in Australia and love the hand-pressed EVOO [extra virgin olive oil], which I can buy at a local produce market BUT this study shows that I won’t live a minute longer, and it won’t prevent a heart attack.”
We found no tweets that mentioned the finding from the paper that the diets had no detectable effect on myocardial infarction, death from cardiovascular causes, or death from any cause. The only difference was in the number of people who had strokes, and that showed a very unimpressive P = 0.04.
Neither did we see any tweets that mentioned the truly impressive list of conflicts of interest of the authors, which ran to an astonishing 419 words.
“Dr. Estruch reports serving on the board of and receiving lecture fees from the Research Foundation on Wine and Nutrition (FIVIN); serving on the boards of the Beer and Health Foundation and the European Foundation for Alcohol Research (ERAB); receiving lecture fees from Cerveceros de España and Sanofi-Aventis; and receiving grant support through his institution from Novartis. Dr. Ros reports serving on the board of and receiving travel support, as well as grant support through his institution, from the California Walnut Commission; serving on the board of the Flora Foundation (Unilever). . . “
And so on, for another 328 words.
The interesting question is how such a paper came to be published in the hugely prestigious New England Journal of Medicine. That it happened is yet another reason to distrust impact factors. It seems to be another sign that glamour journals are more concerned with trendiness than quality.
One sign of that is the fact that the journal’s own tweet misrepresented the work. The irresponsible spin in this initial tweet from the journal started the ball rolling, and after this point, the content of the paper itself became irrelevant. The altmetrics score is utterly disconnected from the science reported in the paper: it more closely reflects wishful thinking and confirmation bias.
The fourth paper in the altmetrics top 100 is an equally instructive example.
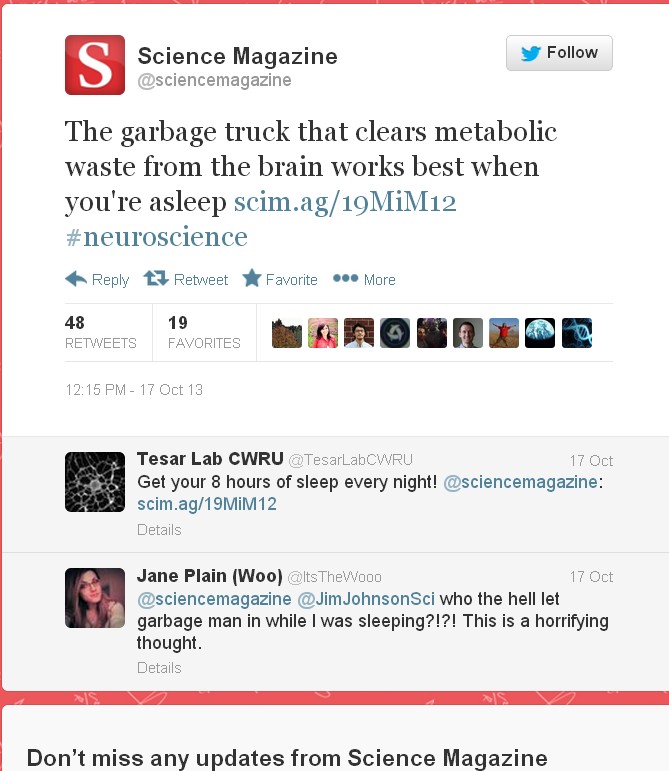
|
This work was also published in a glamour journal, Science. The paper claimed that a function of sleep was to “clear metabolic waste from the brain”. It was initially promoted (inaccurately) on Twitter by the publisher of Science. After that, the paper was retweeted many times, presumably because everybody sleeps, and perhaps because the title hinted at the trendy, but fraudulent, idea of “detox”. Many tweets were variants of “The garbage truck that clears metabolic waste from the brain works best when you’re asleep”. |
|
But this paper was hidden behind Science’s paywall. It’s bordering on irresponsible for journals to promote on social media papers that can’t be read freely. It’s unlikely that anyone outside academia had read it, and therefore few of the tweeters had any idea of the actual content, or the way the research was done. Nevertheless it got “1,479 tweets from 1,355 accounts with an upper bound of 1,110,974 combined followers”. It had the huge Altmetrics score of 1848, the highest altmetric score in October 2013.
Within a couple of days, the story fell out of the news cycle. It was not a bad paper, but neither was it a huge breakthrough. It didn’t show that naturally-produced metabolites were cleared more quickly, just that injected substances were cleared faster when the mice were asleep or anaesthetised. This finding might or might not have physiological consequences for mice.
Worse, the paper also claimed that “Administration of adrenergic antagonists induced an increase in CSF tracer influx, resulting in rates of CSF tracer influx that were more comparable with influx observed during sleep or anesthesia than in the awake state”. Simply put, giving the sleeping mice a drug could reduce the clearance to wakeful levels. But nobody seemed to notice the absurd concentrations of antagonists that were used in these experiments: “adrenergic receptor antagonists (prazosin, atipamezole, and propranolol, each 2 mM) were then slowly infused via the cisterna magna cannula for 15 min”. Use of such high concentrations is asking for non-specific effects. The binding constant (concentration to occupy half the receptors) for prazosin is less than 1 nM, so infusing 2 mM is working at a million times greater than the concentration that should be effective. That’s asking for non-specific effects. Most drugs at this sort of concentration have local anaesthetic effects, so perhaps it isn’t surprising that the effects resembled those of ketamine.
The altmetrics editor hadn’t noticed the problems and none of them featured in the online buzz. That’s partly because to find it out you had to read the paper (the antagonist concentrations were hidden in the legend of Figure 4), and partly because you needed to know the binding constant for prazosin to see this warning sign.
The lesson, as usual, is that if you want to know about the quality of a paper, you have to read it. Commenting on a paper without knowing anything of its content is liable to make you look like an jackass.
A tale of two papers
Another approach that looks at individual papers is to compare some of one’s own papers. Sadly, UCL shows altmetric scores on each of your own papers. Mostly they are question marks, because nothing published before 2011 is scored. But two recent papers make an interesting contrast. One is from DC’s side interest in quackery, one was real science. The former has an altmetric score of 169, the latter has an altmetric score of 2.
|
The first paper was “Acupuncture is a theatrical placebo”, which was published as an invited editorial in Anesthesia and Analgesia [download pdf]. The paper was scientifically trivial. It took perhaps a week to write. Nevertheless, it got promoted it on twitter, because anything to do with alternative medicine is interesting to the public. It got quite a lot of retweets. And the resulting altmetric score of 169 put it in the top 1% of all articles altmetric have tracked, and the second highest ever for Anesthesia and Analgesia. As well as the journal’s own website, the article was also posted on the DCScience.net blog (May 30, 2013) where it soon became the most viewed page ever (24,468 views as of 23 November 2013), something that altmetrics does not seem to take into account. |

|
Compare this with the fate of some real, but rather technical, science.
|
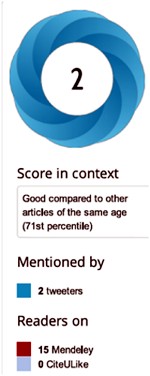
My [DC] best scientific papers are too old (i.e. before 2011) to have an altmetrics score, but my best score for any scientific paper is 2. This score was for Colquhoun & Lape (2012) “Allosteric coupling in ligand-gated ion channels”. It was a commentary with some original material. The altmetric score was based on two tweets and 15 readers on Mendeley. The two tweets consisted of one from me (“Real science; The meaning of allosteric conformation changes http://t.co/zZeNtLdU ”). The only other tweet as abusive one from a cyberstalker who was upset at having been refused a job years ago. Incredibly, this modest achievement got it rated “Good compared to other articles of the same age (71st percentile)”. |
|
Conclusions about bibliometrics
Bibliometricians spend much time correlating one surrogate outcome with another, from which they learn little. What they don’t do is take the time to examine individual papers. Doing that makes it obvious that most metrics, and especially altmetrics, are indeed an ill-conceived and meretricious idea. Universities should know better than to subscribe to them.
Although altmetrics may be the silliest bibliometric idea yet, much this criticism applies equally to all such metrics. Even the most plausible metric, counting citations, is easily shown to be nonsense by simply considering individual papers. All you have to do is choose some papers that are universally agreed to be good, and some that are bad, and see how metrics fail to distinguish between them. This is something that bibliometricians fail to do (perhaps because they don’t know enough science to tell which is which). Some examples are given by Colquhoun (2007) (more complete version at dcscience.net).
Eugene Garfield, who started the metrics mania with the journal impact factor (JIF), was clear that it was not suitable as a measure of the worth of individuals. He has been ignored and the JIF has come to dominate the lives of researchers, despite decades of evidence of the harm it does (e.g.Seglen (1997) and Colquhoun (2003) ) In the wake of JIF, young, bright people have been encouraged to develop yet more spurious metrics (of which ‘altmetrics’ is the latest). It doesn’t matter much whether these metrics are based on nonsense (like counting hashtags) or rely on counting links or comments on a journal website. They won’t (and can’t) indicate what is important about a piece of research- its quality.
People say – I can’t be a polymath. Well, then don’t try to be. You don’t have to have an opinion on things that you don’t understand. The number of people who really do have to have an overview, of the kind that altmetrics might purport to give, those who have to make funding decisions about work that they are not intimately familiar with, is quite small. Chances are, you are not one of them. We review plenty of papers and grants. But it’s not credible to accept assignments outside of your field, and then rely on metrics to assess the quality of the scientific work or the proposal.
It’s perfectly reasonable to give credit for all forms of research outputs, not only papers. That doesn’t need metrics. It’s nonsense to suggest that altmetrics are needed because research outputs are not already valued in grant and job applications. If you write a grant for almost any agency, you can put your CV. If you have a non-publication based output, you can always include it. Metrics are not needed. If you write software, get the numbers of downloads. Software normally garners citations anyway if it’s of any use to the greater community.
When AP recently wrote a criticism of Heather Piwowar’s altmetrics note in Nature, one correspondent wrote: "I haven’t read the piece [by HP] but I’m sure you are mischaracterising it". This attitude summarizes the too-long-didn’t-read (TLDR) culture that is increasingly becoming accepted amongst scientists, and which the comparisons above show is a central component of altmetrics.
Altmetrics are numbers generated by people who don’t understand research, for people who don’t understand research. People who read papers and understand research just don’t need them and should shun them.
But all bibliometrics give cause for concern, beyond their lack of utility. They do active harm to science. They encourage “gaming” (a euphemism for cheating). They encourage short-term eye-catching research of questionable quality and reproducibility. They encourage guest authorships: that is, they encourage people to claim credit for work which isn’t theirs. At worst, they encourage fraud.
No doubt metrics have played some part in the crisis of irreproducibility that has engulfed some fields, particularly experimental psychology, genomics and cancer research. Underpowered studies with a high false-positive rate may get you promoted, but tend to mislead both other scientists and the public (who in general pay for the work). The waste of public money that must result from following up badly done work that can’t be reproduced but that was published for the sake of “getting something out” has not been quantified, but must be considered to the detriment of bibliometrics, and sadly overcomes any advantages from rapid dissemination. Yet universities continue to pay publishers to provide these measures, which do nothing but harm. And the general public has noticed.
It’s now eight years since the New York Times brought to the attention of the public that some scientists engage in puffery, cheating and even fraud.
Overblown press releases written by journals, with connivance of university PR wonks and with the connivance of the authors, sometimes go viral on social media (and so score well on altmetrics). Yet another example, from Journal of the American Medical Association involved an overblown press release from the Journal about a trial that allegedly showed a benefit of high doses of Vitamin E for Alzheimer’s disease.
This sort of puffery harms patients and harms science itself.
We can’t go on like this.
What should be done?
Post publication peer review is now happening, in comments on published papers and through sites like PubPeer, where it is already clear that anonymous peer review can work really well. New journals like eLife have open comments after each paper, though authors do not seem to have yet got into the habit of using them constructively. They will.
It’s very obvious that too many papers are being published, and that anything, however bad, can be published in a journal that claims to be peer reviewed . To a large extent this is just another example of the harm done to science by metrics –the publish or perish culture.
Attempts to regulate science by setting “productivity targets” is doomed to do as much harm to science as it has in the National Health Service in the UK. This has been known to economists for a long time, under the name of Goodhart’s law.
Here are some ideas about how we could restore the confidence of both scientists and of the public in the integrity of published work.
- Nature, Science, and other vanity journals should become news magazines only. Their glamour value distorts science and encourages dishonesty.
- Print journals are overpriced and outdated. They are no longer needed. Publishing on the web is cheap, and it allows open access and post-publication peer review. Every paper should be followed by an open comments section, with anonymity allowed. The old publishers should go the same way as the handloom weavers. Their time has passed.
- Web publication allows proper explanation of methods, without the page, word and figure limits that distort papers in vanity journals. This would also make it very easy to publish negative work, thus reducing publication bias, a major problem (not least for clinical trials)
- Publish or perish has proved counterproductive. It seems just as likely that better science will result without any performance management at all. All that’s needed is peer review of grant applications.
- Providing more small grants rather than fewer big ones should help to reduce the pressure to publish which distorts the literature. The ‘celebrity scientist’, running a huge group funded by giant grants has not worked well. It’s led to poor mentoring, and, at worst, fraud. Of course huge groups sometimes produce good work, but too often at the price of exploitation of junior scientists
- There is a good case for limiting the number of original papers that an individual can publish per year, and/or total funding. Fewer but more complete and considered papers would benefit everyone, and counteract the flood of literature that has led to superficiality.
- Everyone should read, learn and inwardly digest Peter Lawrence’s The Mismeasurement of Science.
A focus on speed and brevity (cited as major advantages of altmetrics) will help no-one in the end. And a focus on creating and curating new metrics will simply skew science in yet another unsatisfactory way, and rob scientists of the time they need to do their real job: generate new knowledge.
It has been said
“Creation is sloppy; discovery is messy; exploration is dangerous. What’s a manager to do?
The answer in general is to encourage curiosity and accept failure. Lots of failure.”
And, one might add, forget metrics. All of them.
Follow-up
17 Jan 2014
This piece was noticed by the Economist. Their ‘Writing worth reading‘ section said
"Why you should ignore altmetrics (David Colquhoun) Altmetrics attempt to rank scientific papers by their popularity on social media. David Colquohoun [sic] argues that they are “for people who aren’t prepared to take the time (or lack the mental capacity) to evaluate research by reading about it.”"
20 January 2014.
Jason Priem, of ImpactStory, has responded to this article on his own blog. In Altmetrics: A Bibliographic Nightmare? he seems to back off a lot from his earlier claim (cited above) that altmetrics are useful for making decisions about hiring or tenure. Our response is on his blog.
20 January 2014.
Jason Priem, of ImpactStory, has responded to this article on his own blog, In Altmetrics: A bibliographic Nightmare? he seems to back off a lot from his earlier claim (cited above) that altmetrics are useful for making decisions about hiring or tenure. Our response is on his blog.
23 January 2014
The Scholarly Kitchen blog carried another paean to metrics, A vigorous discussion followed. The general line that I’ve followed in this discussion, and those mentioned below, is that bibliometricians won’t qualify as scientists until they test their methods, i.e. show that they predict something useful. In order to do that, they’ll have to consider individual papers (as we do above). At present, articles by bibliometricians consist largely of hubris, with little emphasis on the potential to cause corruption. They remind me of articles by homeopaths: their aim is to sell a product (sometimes for cash, but mainly to promote the authors’ usefulness).
It’s noticeable that all of the pro-metrics articles cited here have been written by bibliometricians. None have been written by scientists.
28 January 2014.
Dalmeet Singh Chawla,a bibliometrician from Imperial College London, wrote a blog on the topic. (Imperial, at least in its Medicine department, is notorious for abuse of metrics.)
29 January 2014 Arran Frood wrote a sensible article about the metrics row in Euroscientist.
2 February 2014 Paul Groth (a co-author of the Altmetrics Manifesto) posted more hubristic stuff about altmetrics on Slideshare. A vigorous discussion followed.
5 May 2014. Another vigorous discussion on ImpactStory blog, this time with Stacy Konkiel. She’s another non-scientist trying to tell scientists what to do. The evidence that she produced for the usefulness of altmetrics seemed pathetic to me.
7 May 2014 A much-shortened version of this post appeared in the British Medical Journal (BMJ blogs)
Here is a record of a couple of recent newspaper pieces. Who says the mainstream media don’t matter any longer? Blogs may be in the lead now when it comes to critical analysis. The best blogs have more expertise and more time to read the sources than journalists. But the mainstream media get the message to a different, and much larger, audience.
The Observer ran a whole page interview with me as part of their “Rational Heroes” series. I rather liked their subtitle [pdf of article]
“Professor of pharmacology David Colquhoun is the take-no-prisoners debunker of pseudoscience on his unmissable blog”
It was pretty accurate apart from the fact that the picture was labelled as “DC in his office”. Actually it was taken (at the insistence of the photographer) in Lucia Sivilotti’s lab.

Photo by Karen Robinson.
The astonishing result of this was that on Sunday the blog got a record 24,305 hits. Normally it gets 1,000-1,400 hits a day . between posts, fewer on Sunday, and the previous record was around 7000/day
A week later it was still twice normal. It remains to be seen whether the eventual plateau stays up.
I also gained around 1000 extra followers on twitter, though some dropped away quite soon, and 100 or so people signed for email updates. The dead tree media aren’t yet dead. I’m happy to say.
3 June 2013
Perhaps as a result of the foregoing piece, I got asked to write a column for The Observer, at barely 48 hours notice. This is the best I could manage in the time. The web version has links.

This attracted the usual "it worked for me" anecdotes in the comments, but I spent an afternoon answering them. It seems important to have a dialogue, not just to lecture the public. In fact when I read a regular scientific paper, I now find myself looking for the comment section. That may say something about the future of scientific publishing.
It is for others to judge how succesfully I engage with the public, but I was quite surprised to discover that UCL’s public engagement unit, @UCL_in_public, has blocked me on twitter. Hey ho. They have 1574 follower and I have 7597. I wish them the best of luck.
Follow-up
Academic staff are going to be fired at Queen Mary University of London (QMUL). It’s possible that universities may have to contract a bit in hard times, so what’s wrong?
What’s wrong is that the victims are being selected in a way that I can describe only as insane. The criteria they use are guaranteed to produce a generation of second-rate spiv scientists, with a consequent progressive decline in QMUL’s reputation.
The firings, it seems, are nothing to do with hard financial times, but are a result of QMUL’s aim to raise its ranking in university league tables.
In the UK university league table, a university’s position is directly related to its government research funding. So they need to do well in the 2014 ‘Research Excellence Framework’ (REF). To achieve that they plan to recruit new staff with high research profiles, take on more PhD students and post-docs, obtain more research funding from grants, and get rid of staff who are not doing ‘good’ enough research.
So far, that’s exactly what every other university is trying to do. This sort of distortion is one of the harmful side-effects of the REF. But what’s particularly stupid about QMUL’s behaviour is the way they are going about it. You can assess your own chances of survival at QMUL’s School of Biological and Chemical Sciences from the following table, which is taken from an article by Jeremy Garwood (Lab Times Online. July 4, 2012). The numbers refer to the four year period from 2008 to 2011.
|
Category of staff |
Research Output Quantity |
Research Output |
Research Income (£) |
Research Income (£) |
|
Professor |
11 |
2 |
400,000 |
at least 200,000 |
|
Reader |
9 |
2 |
320,000 |
at least 150,000 |
|
Senior Lecturer |
7 |
1 |
260,000 |
at least 120,000 |
|
Lecturer |
5 |
1 |
200,000 |
at least 100,000 |
|
In addition to the three criteria, ‘Research Output ‐ quality’, ‘Research Output – quantity’, and ‘Research Income’, there is a minimum threshold of 1 PhD completion for staff at each academic level. All this data is “evidenced by objective metrics; publications cited in Web of Science, plus official QMUL metrics on grant income and PhD completion.” To survive, staff must meet the minimum threshold in three out of the four categories, except as follows: Demonstration of activity at an exceptional level in either ‘research outputs’ or ‘research income’, termed an ‘enhanced threshold’, is “sufficient” to justify selection regardless of levels of activity in the other two categories. And what are these enhanced thresholds? |
|
The university notes that the above criteria “are useful as entry standards into the new school, but they fall short of the levels of activity that will be expected from staff in the future. These metrics should not, therefore, be regarded as targets for future performance.” This means that those who survived the redundancy criteria will simply have to do better. But what is to reassure them that it won’t be their turn next time should they fail to match the numbers? To help them, Queen Mary is proposing to introduce ‘D3’ performance management (www.unions.qmul.ac.uk/ucu/docs/d3-part-one.doc). Based on more ‘administrative physics’, D3 is shorthand for ‘Direction × Delivery × Development.’ Apparently “all three are essential to a successful team or organisation. The multiplication indicates that where one is absent/zero, then the sum is zero!” D3 is based on principles of accountability: “A sign of a mature organisation is where its members acknowledge that they face choices, they make commitments and are ready to be held to account for discharging these commitments, accepting the consequences rather than seeking to pass responsibility.” Inspired? |
I presume the D3 document must have been written by an HR person. It has all the incoherent use of buzzwords so typical of HR. And it says "sum" when it means "product" (oh dear, innumeracy is rife).
The criteria are utterly brainless. The use of impact factors for assessing people has been discredited at least since Seglen (1997) showed that the number of citations that a paper gets is not perceptibly correlated with the impact factor of the journal in which it’s published. The reason for this is the distribution of the number of citations for papers in a particular journal is enormously skewed. This means that high-impact journals get most of their citations from a few articles.
|
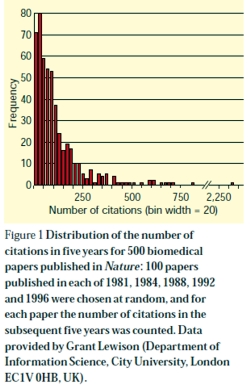
The distribution for Nature is shown in Fig. 1. Far from being gaussian, it is even more skewed than a geometric distribution; the mean number of citations is 114, but 69% of papers have fewer than the mean, and 24% have fewer than 30 citations. One paper has 2,364 citations but 35 have 10 or fewer. ISI data for citations in 2001 of the 858 papers published in Nature in 1999 show that the 80 most-cited papers (16% of all papers) account for half of all the citations (from Colquhoun, 2003)
|
|
The Institute of Scientific Information, ISI, is guilty of the unsound statistical practice of characterizing a distribution by its mean only, with no indication of its shape or even its spread. School of Biological and Chemical Sciences-QMUL is expecting everyone has to be above average in the new regime. Anomalously, the thresholds for psychologists are lower because it is said that it’s more difficult for them to get grants. This undermines even the twisted logic applied at the outset.
All this stuff about skewed distributions is, no doubt, a bit too technical for HR people to understand. Which, of course, is precisely why they should have nothing to do with assessing people.
At a time when so may PhDs fail to get academic jobs we should be limiting the numbers. But QMUL requires everyone to have a PhD student, not for the benefit of the student, but to increase its standing in league tables. That is deeply unethical.
The demand to have two papers in journals with impact factor greater than seven is nonsense. In physiology, for example, there are only four journals with an impact factor greater that seven and three of them are review journals that don’t publish original research. The two best journals for electrophysiology are Journal of Physiology (impact factor 4.98, in 2010) and Journal of General Physiology (IF 4.71). These are the journals that publish papers that get you into the Royal Society or even Nobel prizes. But for QMUL, they don’t count.
I have been lucky to know well three Nobel prize winners. Andrew Huxley. Bernard Katz, and Bert Sakmann. I doubt that any of them would pass the criteria laid down for a professor by QMUL. They would have been fired.
The case of Sakmann is analysed in How to Get Good Science, [pdf version]. In the 10 years from 1976 to 1985, when Sakmann rose to fame, he published an average of 2.6 papers per year (range 0 to 6). In two of these 10 years he had no publications at all. In the 4 year period (1976 – 1979 ) that started with the paper that brought him to fame (Neher & Sakmann, 1976) he published 9 papers, just enough for the Reader grade, but in the four years from 1979 – 1982 he had 6 papers, in 2 of which he was neither first nor last author. His job would have been in danger if he’d worked at QMUL. In 1991 Sakmann, with Erwin Neher, got the Nobel Prize for Physiology or Medicine.
The most offensive thing of the lot is the way you can buy yourself out if you publish 26 papers in the 4 year period. Sakmann came nowhere near this. And my own total, for the entire time from my first paper (1963) until I was elected to the Royal Society (May 1985) was 27 papers (and 7 book chapters). I would have been fired.
Peter Higgs had no papers at all from the time he moved to Edinburgh in 1960, until 1964 when his two paper’s on what’s now called the Higgs’ Boson were published in Physics Letters. That journal now has an impact factor less than 7 so Queen Mary would not have counted them as “high quality” papers, and he would not have been returnable for the REF. He too would have been fired.
The encouragement to publish large numbers of papers is daft. I have seen people rejected from the Royal Society for publishing too much. If you are publishing a paper every six weeks, you certainly aren’t writing them, and possibly not even reading them. Most likely you are appending your name to somebody else’s work with little or no checking of the data. Such numbers can be reached only by unethical behaviour, as described by Peter Lawrence in The Mismeasurement of Science. Like so much managerialism, the rules provide an active encouragement to dishonesty.
In the face of such a boneheaded approach to assessment of your worth, it’s the duty of any responsible academic to point out the harm that’s being done to the College. Richard Horton, in the Lancet, did so in Bullying at Barts. There followed quickly letters from Stuart McDonald and Nick Wright, who used the Nuremburg defence, pointing out that the Dean (Tom Macdonald) was just obeying orders from above. That has never been as acceptable defence. If Macdonald agreed with the procedure, he should be fired for incompetence. If he did not agree with it he should have resigned.
It’s a pity, because Tom Macdonald was one of the people with whom I corresponded in support of Barts’ students who, very reasonably, objected to having course work marked by homeopaths (see St Bartholomew’s teaches antiscience, but students revolt, and, later, Bad medicine. Barts sinks further into the endarkenment). In that case he was not unreasonable, and, a mere two years later I heard that he’d taken action.
To cap it all, two academics did their job by applying a critical eye to what’s going on at Queen Mary. They wrote to the Lancet under the title Queen Mary: nobody expects the Spanish Inquisition
"For example, one of the “metrics” for research output at professorial level is to have published at least two papers in journals with impact factors of 7 or more. This is ludicrous, of course—a triumph of vanity as sensible as selecting athletes on the basis of their brand of track suit. But let us follow this “metric” for a moment. How does the Head of School fair? Zero, actually. He fails. Just consult Web of Science. Take care though, the result is classified information. HR’s “data” are marked Private and Confidential. Some things must be believed. To question them is heresy."
Astoundingly, the people who wrote this piece are now under investigation for “gross misconduct”. This is behaviour worthy of the University of Poppleton, as pointed out by the inimitable Laurie Taylor, in Times Higher Education (June 7)
|
The rustle of censorship It appears that last week’s edition of our sister paper, The Poppleton Evening News, carried a letter from Dr Gene Ohm of our Biology Department criticising this university’s metrics-based redundancy programme. We now learn that, following the precedent set by Queen Mary, University of London, Dr Ohm could be found guilty of “gross misconduct” and face “disciplinary proceedings leading to dismissal” for having the effrontery to raise such issues in a public place. Louise Bimpson, the corporate director of our ever-expanding human resources team, admitted that this response might appear “severe” but pointed out that Poppleton was eager to follow the disciplinary practices set by such soon-to-be members of the prestigious Russell Group as Queen Mary. Thus it was only to be expected that we would seek to emulate its espousal of draconian censorship. She hoped this clarified the situation. |
David Bignell, emeritus professor of zoology at Queen Mary hit the nail on the head.
"These managers worry me. Too many are modest achievers, retired from their own studies, intoxicated with jargon, delusional about corporate status and forever banging the metrics gong. Crucially, they don’t lead by example."
What the managers at Queen Mary have failed to notice is that the best academics can choose where to go.
People are being told to pack their bags and move out with one day’s notice. Access to journals stopped, email address removed, and you may need to be accompanied to your (ex)-office. Good scientists are being treated like criminals.
What scientist in their right mind would want to work at QMUL, now that their dimwitted assessment methods, and their bullying tactics, are public knowledge?
The responsibility must lie with the principal, Simon Gaskell. And we know what the punishment is for bringing your university into disrepute.
Follow-up
Send an email. You may want to join the many people who have already written to QMUL’s principal, Simon Gaskell (principal@qmul.ac.uk), and/or to Sir Nicholas Montagu, Chairman of Council, n.montagu@qmul.ac.uk.
Sunday 1 July 2012. Since this blog was posted after lunch on Friday 29th June, it has had around 9000 visits from 72 countries. Here is one of 17 maps showing the origins of 200 of the hits in the last two days
The tweets about QMUL are collected in a Storify timeline.
I’m reminded of a 2008 comment, on a post about the problems imposed by HR, In-human resources, science and pizza.
Thanks for that – I LOVED IT. It’s fantastic that the truth of HR (I truly hate that phrase) has been so ruthlessly exposed. Should be part of the School Handbook. Any VC who stripped out all the BS would immediately retain and attract good people and see their productivity soar.
That’s advice that Queen Mary should heed.
Part of the reason for that popularity was Ben Goldacre’s tweet, to his 201,000 followers
“destructive, unethical and crude metric incentives in academia (spotlight QMUL) bit.ly/MFHk2H by @david_colquhoun”
3 July 2012. I have come by a copy of this email, which was sent to Queen Mary by a senior professor from the USA (word travels fast on the web). It shows just how easy it is to destroy the reputation of an institution.
|
Sir Nicholas Montagu, Chairman of Council, and Principal Gaskell, I was appalled to read the criteria devised by your University to evaluate its faculty. There are so flawed it is hard to know where to begin. Your criteria are antithetical to good scientific research. The journals are littered with weak publications, which are generated mainly by scientists who feel the pressure to publish, no matter whether the results are interesting, valid, or meaningful. The literature is flooded by sheer volume of these publications. Your attempt to require “quality” research is provided by the requirement for publications in “high Impact Factor” journals. IF has been discredited among scientists for many reasons: it is inaccurate in not actually reflecting the merit of the specific paper, it is biased toward fields with lots of scientists, etc. The demand for publications in absurdly high IF journals encourages, and practically enforces scientific fraud. I have personally experienced those reviews from Nature demanding one or two more “final” experiments that will clinch the publication. The authors KNOW how these experiments MUST turn out. If they want their Nature paper (and their very academic survival if they are at a brutal, anti-scientific university like QMUL), they must get the “right” answer. The temptation to fudge the data to get this answer is extreme. Some scientists may even be able to convince themselves that each contrary piece of data that they discard to ensure the “correct” answer is being discarded for a valid reason. But the result is that scientific misconduct occurs. I did not see in your criteria for “success” at QMUL whether you discount retracted papers from the tally of high IF publications, or perhaps the retraction itself counts as yet another high IF publication! Your requirement for each faculty to have one or more postdocs or students promotes the abusive exploitation of these individuals for their cheap labor, and ignores the fact that they are being “trained” for jobs that do not exist. The “standards” you set are fantastically unrealistic. For example, funding is not graded, but a sharp step function – we have 1 or 2 or 0 grants and even if the average is above your limits, no one could sustain this continuously. Once you have fired every one of your faculty, which will almost certainly happen within 1-2 rounds of pogroms, where will you find legitimate scientists who are willing to join such a ludicrous University? |
4 July 2012.
Professor John F. Allen is Professor of Biochemistry at Queen Mary, University of London, and distinguished in the fields of Photosynthesis, Chloroplasts, Mitochondria, Genome function and evolution and Redox signalling. He, with a younger colleague, wrote a letter to the Lancet, Queen Mary: nobody expects the Spanish Inquisition. It is an admirable letter, the sort of thing any self-respecting academic should write. But not according to HR. On 14 May, Allen got a letter from HR, which starts thus.
|
14th May 2012 Dear Professor Allen I am writing to inform you that the College had decided to commence a factfinding investigation into the below allegation: That in writing and/or signing your name to a letter entitled "Queen Mary: nobody expects the Spanish Inquisition," (enclosed) which was published in the Lancet online on 4th May 2012, you sought to bring the Head of School of Biological and Chemical Sciences and the Dean for Research in the School of Medicine and Dentistry into disrepute. . . . . Sam Holborn |
Download the entire letter. It is utterly disgraceful bullying. If anyone is bringing Queen Mary into disrepute, it is Sam Holborn and the principal, Simon Gaskell.
Here’s another letter, from the many that have been sent. This is from a researcher in the Netherlands.
|
Dear Sir Nicholas,
I am addressing this to you in the hope that you were not directly involved in creating this extremely stupid set of measures that have been thought up, not to improve the conduct of science at QMUL, but to cheat QMUL’s way up the league tables over the heads of the existing academic staff. Others have written more succinctly about the crass stupidity of your Human Resources department than I could, and their apparent ignorance of how science actually works. As your principal must bear full responsibility for the introduction of these measures, I am not sending him a copy of this mail. I am pretty sure that his “principal” mail address will no longer be operative. We have had a recent scandal in the Netherlands where a social psychology professor, who even won a national “Man of the Year” award, as well as as a very large amount of research money, was recently exposed as having faked all the data that went into a total number of articles running into three figures. This is not the sort of thing one wants to happen to one’s own university. He would have done well according to your REF .. before he was found out. Human Resources departments have gained too much power, and are completely incompetent when it comes to judging academic standards. Let them get on with the old dull, and gobbledigook-free, tasks that personnel departments should be carrying out. |
5 July 2012.
Here’s another letter. It’s from a member of academic staff at QMUL, someone who is not himself threatened with being fired. It certainly shows that I’m not making a fuss about nothing. Rather, I’m the only person old enough to say what needs to be said without fear of losing my job and my house.
|
Dear Prof. Colquhoun,
I am an academic staff member in SBCS, QMUL. I am writing from my personal email account because the risks of using my work account to send this email are too great. I would like to thank you for highlighting our problems and how we have been treated by our employer (Queen Mary University of London), in your blog. I would please urge you to continue to tweet and blog about our plight, and staff in other universities experiencing similarly horrific working conditions. I am not threatened with redundancy by QMUL, and in fact my research is quite successful. Nevertheless, the last nine months have been the most stressful of all my years of academic life. The best of my colleagues in SBCS, QMUL are leaving already and I hope to leave, if I can find another job in London. Staff do indeed feel very unfairly treated, intimidated and bullied. I never thought a job at a university could come to this.
Thank you again for your support. It really does matter to the many of us who cannot really speak out openly at present.
Best regards,
|
In a later letter, the same person pointed out
"There are many of us who would like to speak more openly, but we simply cannot."
"I have mortgage . . . . Losing my job would probably mean losing my home too at this point."
"The plight of our female staff has not even been mentioned. We already had very few female staff. And with restructuring, female staff are more likely to be forced into teaching-only contracts or indeed fired"."
"total madness in the current climate – who would want to join us unless desperate for a job!"
“fuss about nothing” – absolutely not. It is potentially a perfect storm leading to teaching and research disaster for a university! Already the reputation of our university has been greatly damaged. And senior staff keep blaming and targeting the “messengers"."
6 July 2012.
Througn the miracle of WiFi, this is coming from Newton, MA. The Lancet today has another editorial on the Queen Mary scandal.
"As hopeful scientists prepare their applications to QMUL, they should be aware that, behind the glossy advertising, a sometimes harsh, at times repressive, and disturbingly unforgiving culture awaits them."
That sums it up nicely.
24 July 2012. I’m reminded by Nature writer, Richard van Noorden (@Richvn) that Nature itself has wriiten at least twice about the iniquity of judging people by impact factors. In 2005 Not-so-deep impact said
"Only 50 out of the roughly 1,800 citable items published in those two years received more than 100 citations in 2004. The great majority of our papers received fewer than 20 citations."
"None of this would really matter very much, were it not for the unhealthy reliance on impact factors by administrators and researchers’ employers worldwide to assess the scientific quality of nations and institutions, and often even to judge individuals."
And, more recently, in Assessing assessment” (2010).
29 July 2012. Jonathan L Rees. of the University of Edinburgh, ends his blog:
"I wonder what career advice I should offer to a young doctor circa 2012. Apart from not taking a job at Queen Mary of course. "
How to select candidates
I have, at various times, been asked how I would select candidates for a job, if not by counting papers and impact factors. This is a slightly modified version of a comment that I left on a blog, which describes roughly what I’d advocate
After a pilot study the entire Research Excellence Framework (which attempts to assess the quality of research in every UK university) made the following statement.
“No sub-panel will make any use of journal impact factors, rankings, lists or the perceived standing of publishers in assessing the quality of research outputs”
It seems that the REF is paying attention to the science not to bibliometricians.
It has been the practice at UCL to ask people to nominate their best papers (2 -4 papers depending on age). We then read the papers and asked candidates hard questions about them (not least about the methods section). It’s a method that I learned a long time ago from Stephen Heinemann, a senior scientist at the Salk Institute. It’s often been surprising to learn how little some candidates know about the contents of papers which they themselves select as their best. One aim of this is to find out how much the candidate understands the principles of what they are doing, as opposed to following a recipe.
Of course we also seek the opinions of people who know the work, and preferably know the person. Written references have suffered so much from ‘grade inflation’ that they are often worthless, but a talk on the telephone to someone that knows both the work, and the candidate, can be useful, That, however, is now banned by HR who seem to feel that any knowledge of the candidate’s ability would lead to bias.
It is not true that use of metrics is universal and thank heavens for that. There are alternatives and we use them.
Incidentally, the reason that I have described the Queen Mary procedures as insane, brainless and dimwitted is because their aim to increase their ratings is likely to be frustrated. No person in their right mind would want to work for a place that treats its employees like that, if they had any other option. And it is very odd that their attempt to improve their REF rating uses criteria that have been explicitly ruled out by the REF. You can’t get more brainless than that.
This discussion has been interesting to me, if only because it shows how little bibliometricians understand how to get good science.
Open access is in the news again.
Index on Censorship held a debate on open data on December 6th.
|
The video of of the meeting is now on YouTube. A couple of dramatic moments in the video: At 48 min O’Neill & Monbiot face off about "competent persons" (and at 58 min Walport makes fun of my contention that it’s better to have more small grants rather than few big ones, on the grounds that it’s impossible to select the stars). |

|
The meeting has been written up on the Bishop Hill Blog, with some very fine cartoon minutes.
 (I love the Josh cartoons -pity he seems to be a climate denier, spoken of approvingly by the unspeakable James Delingpole.)
(I love the Josh cartoons -pity he seems to be a climate denier, spoken of approvingly by the unspeakable James Delingpole.)
It was gratifying that my remarks seemed to be better received by the scientists in the audience than they were by some other panel members. The Bishop Hill blog comments "As David Colquhoun, the only real scientist there and brilliant throughout, said “Give them everything!” " Here’s a subsection of the brilliant cartoon minutes

The bit about "I just lied -but he kept his job" referred to the notorious case of Richard Eastell and the University of Sheffield.
We all agreed that papers should be open for anyone to read, free. Monbiot and I both thought that raw data should be available on request, though O’Neill and Walport had a few reservations about that.
A great deal of time and money would be saved if data were provided on request. It shouldn’t need a Freedom of Information Act (FOIA) request, and the time and energy spent on refusing FOIA requests is silly. It simply gives the impression that there is something to hide (Climate scientists must be ruthlessly honest about data). The University of Central Lancashire spent £80,000 of taxpayers’ money trying (unsuccessfully) to appeal against the judgment of the Information Commissioner that they must release course material to me. It’s hard to think of a worse way to spend money.
A few days ago, the Department for Business, Innovation and Skills (BIS) published a report which says (para 6.6)
“The Government . . . is committed to ensuring that publicly-funded research should be accessible
free of charge.”
That’s good, but how it can be achieved is less obvious. Scientific publishing is, at the moment, an unholy mess. It’s a playground for profiteers. It runs on the unpaid labour of academics, who work to generate large profits for publishers. That’s often been said before, recently by both George Monbiot (Academic publishers make Murdoch look like a socialist) and by me (Publish-or-perish: Peer review and the corruption of science). Here are a few details.
Extortionate cost of publishing
Mark Walport has told me that
The Wellcome Trust is currently spending around £3m pa on OA publishing costs and, looking at the Wellcome papers that find their way to UKPMC, we see that around 50% of this content is routed via the “hybrid option”; 40% via the “pure” OA journals (e.g. PLoS, BMC etc), and the remaining 10% through researchers self-archiving their author manuscripts.
I’ve found some interesting numbers, with help from librarians, and through access to The Journal Usage Statistics Portal (JUSP).
Elsevier
UCL pays Elsevier the astonishing sum of €1.25 million, for access to its journals. And that’s just one university. That price doesn’t include any print editions at all, just web access and there is no open access. You have to have a UCL password to see the results. Elsevier has, of course, been criticised before, and not just for its prices.
Elsevier publish around 2700 scientific journals. UCL has bought a package of around 2100 journals. There is no possibility to pick the journals that you want. Some of the journals are used heavily ("use" means access of full text on the web). In 2010, the most heavily used journal was The Lancet, followed by four Cell Press journals
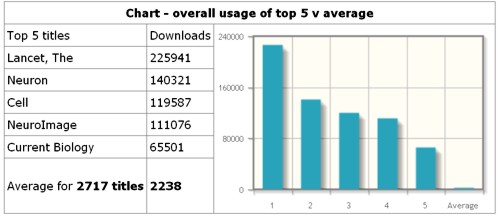
But notice the last bin. Most of the journals are hardly used at all. Among all Elsevier journals, 251 were not accessed even once in 2010. Among the 2068 journals bought by UCL, 56 were never accessed in 2010 and the most frequent number of accesses per year is between 1 and 10 (the second bin in the histogram, below). 60 percent of journals have 300 or fewer usages in 2010, Above 300, the histogram tails on up to 51878 accesses for The Lancet. The remaining 40 percent of journals are represented by the last bin (in red). The distribution is exceedingly skewed. The median is 187, i.e. half of the journals had fewer than 187 usages in 2010), but the mean number of usages (which is misleading for such a skewed distribution, was 662 usages).
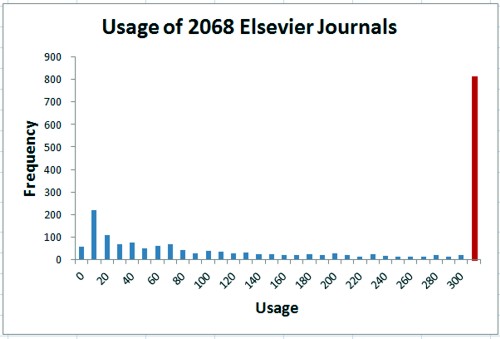
Nature Publishing Group
UCL bought 65 journals from NPG in 2010. They get more use than Elsevier, though surprisingly three of them were never accessed in 2010, and 17 had fewer than 1000 accesses in that year. The median usage was 2412, better than most. The leader, needless to say, was Nature itself, with 153,321.
Oxford University Press
The situation is even more extreme for 248 OUP journals, perhaps because many of the journals are arts or law rather than science.
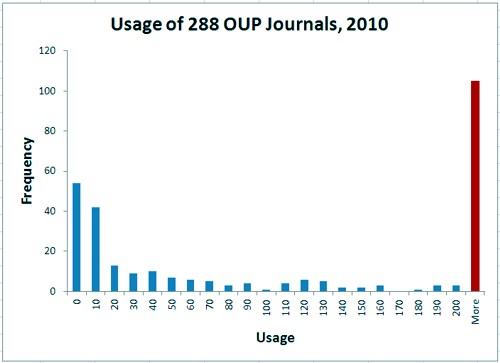
The most frequent (modal) usage of was zero (54 journals), followed by 1 to 10 accesses (42 journals) 64 percent of journals had fewer than 200 usages, and the 36 percent with over 200 are pooled in the last (red) bin. The histogram extends right up to 16060 accesses for Brain. The median number of usages in 2010 was 66.
So far I haven’t been able to discover the costs of the contracts with OUP or Nature Publishing group. It seems that the university has agreed to confidentiality clauses. This itself is a shocking lack of transparency. If I can find the numbers I shall -watch this space.
Almost all of these journals are not open access. The academics do the experiments, most often paid for by the taxpayer. They write the paper (and now it has to be in a form that is almost ready for publication without further work), they send it to the journal, where it is sent for peer review, which is also unpaid. The journal sells the product back to the universities for a high price, where the results of the work are hidden from the people who paid for it.
It’s even worse than that, because often the people who did the work and wrote the paper, have to pay "page charges". These vary, but can be quite high. If you send a paper to the Journal of Neuroscience, it will probably cost you about $1000. Other journals, like the excellent Journal of Physiology, don’t charge you to submit a paper (unless you want a colour figure in the print edition, £200), but the paper is hidden from the public for 12 months unless you pay $3000.
The major medical charity, the Wellcome Trust, requires that the work it funds should be available to the public within 6 months of publication. That’s nothing like good enough to allow the public to judge the claims of a paper which hits the newspapers the day that it’s published. Nevertheless it can cost the authors a lot. Elsevier journals charge $3000 except for their most-used journals. The Lancet charges £400 per page and Cell Press journals charge $5000 for this unsatisfactory form of open access.
Open access journals
The outcry about hidden results has resulted in a new generation of truly open access journals that are open to everyone from day one. But if you want to publish in them you have to pay quite a lot.
Furthermore, although all these journals are free to read, most of them do not allow free use of the material they publish. Most are operating under all-rights-reserved copyrights. In 2009 under 10 percent of open access journals had true Creative Commons licence.
Nature Publishing Group has a true open access journal, Nature Communications, but it costs the author $5000 to publish there. The Public Library of Science journals are truly open access but the author is charged $2900 for PLoS Medicine though PLoS One costs the author only $1350
A 2011 report considered the transition to open access publishing but it doesn’t even consider radical solutions, and makes unreasonably low estimates of the costs of open access publishing.
Scam journals have flourished under the open access flag
Open access publishing has, so far, almost always involved paying a hefty fee. That has brought the rats out of the woodwork and one gets bombarded daily with offers to publish in yet another open access journal. Many of these are simply scams. You pay, we put it on the web and we won’t fuss about quality. Luckily there is now a guide to these crooks: Jeffrey Beall’s List of Predatory, Open-Access Publishers.
One that I hear from regularly is Bentham Open Journals
(a name that is particularly inappropriate for anyone at UCL). Jeffery Beall comments
"Among the first, large-scale gold OA publishers, Bentham Open continues to expand its fleet of journals, now numbering over 230. Bentham essentially operates as a scholarly vanity press."
They undercut real journals. A research article in The Open Neuroscience Journal will cost you a mere $800. Although these journals claim to be peer-reviewed, their standards are suspect. In 2009, a nonsensical computer-generated spoof paper was accepted by a Bentham Journal (for $800),
What can be done about publication, and what can be done about grants?
Both grants and publications are peer-reviewed, but the problems need to be discussed separately.
Peer review of papers by journals
One option is clearly to follow the example of the best open access journals, such as PLoS. The cost of $3000 to 5000 per paper would have to be paid by the research funder, often the taxpayer. It would be money subtracted from the research budget, but it would retain the present peer review system and should cost no more if the money that were saved on extortionate journal subscriptions were transferred to research budgets to pay the bills, though there is little chance of this happening.
The cost of publication would, in any case, be minimised if fewer papers were published, which is highly desirable anyway.
But there are real problems with the present peer review system. It works quite well for journals that are high in the hierarchy. I have few grumbles myself about the quality of reviews, and sometimes I’ve benefitted a lot from good suggestions made by reviewers. But for the user, the process is much less satisfactory because peer review has next to no effect on what gets published in journals. All it influences is which journal the paper appears in. The only effect of the vast amount of unpaid time and effort put into reviewing is to maintain a hierarchy of journals, It has next to no effect on what appears in Pubmed.
For authors, peer review can work quite well, but
from the point of view of the consumer, peer review is useless.
It is a myth that peer review ensures the quality of what appears in the literature.
A more radical approach
I made some more radical suggestions in Publish-or-perish: Peer review and the corruption of science.
It seems to me that there would be many advantages if people simply published their own work on the web, and then opened the comments. For a start, it would cost next to nothing. The huge amount of money that goes to publishers could be put to better uses.
Another advantage would be that negative results could be published. And proper full descriptions of methods could be provided because there would be no restrictions on length.
Under that system, I would certainly send a draft paper to a few people I respected for comments before publishing it. Informal consortia might form for that purpose.
The publication bias that results from non-publication of negative results is a serious problem, mainly, but not exclusively, for clinical trials. It is mandatory to register a clinical trial before it starts, but many of the results never appear. (see, for example, Deborah Cohen’s report for Index on Censorship). Although trials now have to be registered before they start, there is no check on whether or not the results are published. A large number of registered trials do not result in any publication, and this publication bias can costs thousands of lives. It is really important to ensure that all results get published,
The ArXiv model
There are many problems that would have to be solved before we could move to self-publication on the web. Some have already been solved by physicists and mathematicians. Their archive, ArXiv.org provides an example of where we should be heading. Papers are published on the web at no cost to either user or reader, and comments can be left. It is an excellent example of post-publication peer review. Flame wars are minimised by requiring users to register, and to show they are bona fide scientists before they can upload papers or comments. You may need endorsement if you haven’t submitted before.
Peer review of grants
The problems for grants are quite different from those for papers. There is no possibility of doing away with peer review for the award of grants, however imperfect the process may be. In fact candidates for the new Wellcome Trust investigator awards were alarmed to find that the short listing of candidates for their new Investigator Awards was done without peer review.
The Wellcome Trust has been enormously important for the support of medical and biological support, and never more than now, when the MRC has become rather chaotic (let’s hope the new CEO can sort it out). There was, therefore, real consternation when Wellcome announced a while ago its intention to stop giving project and programme grants altogether. Instead it would give a few Wellcome Trust Investigator Awards to prominent people. That sounds like the Howard Hughes approach, and runs a big risk of “to them that hath shall be given”.
The awards have just been announced, and there is a good account by Colin Macilwain in Science [pdf]. UCL did reasonable well with four awards, but four is not many for a place the size of UCL. Colin Macilwain hits the nail on the head.
"While this is great news for the 27 new Wellcome Investigators who will share £57 million, hundreds of university-based researchers stand to lose Wellcome funds as the trust phases out some existing programs to pay for the new category of investigators".
There were 750 applications, but on the basis of CV alone, they were pared down to a long-list if 173. The panels then cut this down to a short-list of 55. Up to this point no external referees were used, quite unlike the normal process for award of grants. This seems to me to have been an enormous mistake. No panel, however distinguished, can have the knowledge to distinguish the good from the bad in areas outside their own work, It is only human nature to favour the sort of work you do yourself. The 55 shortlisted people were interviewed, but again by a panel with an even narrower range of expertise, Macilwain again:
"Applications for MRC grants have gone up “markedly” since the Wellcome ones closed, he says: “We still see that as unresolved.” Leszek Borysiewicz, vice-chancellor of the University of Cambridge, which won four awards, believes the impact will be positive: “Universities will adapt to this way of funding research."
It certainly isn’t obvious to most people how Cambridge or UCL will "adapt" to funding of only four people.
The Cancer Research Campaign UK has recently made the same mistake.
One problem is that any scheme of this sort will inevitably favour big groups, most of whom are well-funded already. Since there is some reason to believe that small groups are more productive (see also University Alliance report), it isn’t obvious that this is a good way to go. I was lucky enough to get 45 minutes with the director of the Wellcome Trust, Mark Walport, to put these views. He didn’t agree with all I said, but he did listen.
One of the things that I put to him was a small statistical calculation to illustrate the great danger of a plan that funds very few people. The funding rate was 3.6% of the original applications, and 15.6% of the long-listed applications. Let’s suppose, as a rough approximation, that the 173 long-listed applications were all of roughly equal merit. No doubt that won’t be exactly true, but I suspect it might be more nearly true than the expert panels will admit. A quick calculation in Mathcad gives this, if we assume a 1 in 8 chance of success for each application.
Distribution of the number of successful applications
Suppose $ n $ grant applications are submitted. For example, the same grant submitted $ n $ times to selection boards of equal quality, OR $ n $ different grants of equal merit are submitted to the same board.
Define $ p $ = probability of success at each application
Under these assumptions, it is a simple binomial distribution problem.
According to the binomial distribution, the probability of getting $ r $ successful applications in $ n $ attempts is
\[ P(r)=\frac{n!}{r!\left(n-r\right)! }\; {p}^{r} \left(1-p \right)^{n-r} \]
For a success rate of 1 in 8, $ p = 0.125 $, so if you make $ n = 8 $ applications, the probability that $ r $ of them will succeed is shown in the graph.
Despite equal merit, almost as many people end up with no grant at all as almost as many people end up with no grant at all as get one grant. And 26% of people will get two or more grants.
Of course it would take an entire year to write 8 applications. If we take a more realistic case of making four applications we have $ n = 4 $ (and $ p = 0.125 $, as before). In this case the graph comes out as below. You have a nearly 60% chance of getting nothing at all, and only a 1 in 3 chance of getting one grant.
These results arise regardless of merit, purely as consequence of random chance. They are disastrous, and especially disastrous for the smaller, better-value, groups for which a gap in funding can mean loss of vital expertise. It also has the consequence that scientists have to spend most of their time not doing science, but writing grant applications. The mean number of applications before a success is 8, and a third of people will have to write 9 or more applications before they get funding. This makes very little sense.
Grant-awarding panels are faced with the near-impossible task of ranking many similar grants. The peer review system is breaking down, just as it has already broken down for journal publications.
I think these considerations demolish the argument for funding a small number of ‘stars’. The public might expect that the person making the application would take an active part in the research. Too often, now, they spend most of their time writing grant applications. What we need is more responsive-mode smallish programme grants and a maximum on the size of groups.
Conclusions
We should be thinking about the following changes,
- Limit the number of papers that an individual can publish. This would increase quality, it would reduce the impossible load on peer reviewers and it would reduce costs.
- Limit the size of labs so that more small groups are encouraged. This would increase both quality and value for money.
- More (and so smaller) grants are essential for innovation and productivity.
- Move towards self-publishing on the web so the cost of publishing becomes very low rather than the present extortionate costs. It would also mean that negative results could be published easily and that methods could be described in proper detail.
The entire debate is now on YouTube.
Follow-up
24 January 2012. The eminent mathematician, Tim Gowers, has a rather hard-hitting blog on open access and scientific publishing, Elsevier – my part in its downfall. I’m right with him. Although his post lacks the detailed numbers of mine, it shows that mathematicians has exactly the same problems of the rest of us.
11 April 2012. Thanks to Twitter, I came across a remarkably prescient article, in the Guardian, in 2001.
Science world in revolt at power of the journal owners, by James Meek. Elsevier have been getting away with murder for quite a while.
19 April 2012.
|
I got invited to give after-dinner talk on open access at Cumberland Lodge. It was for the retreat of out GEE Department (that is the catchy brand name we’ve had since 2007: I’m in the equally memorable NPP). I think it stands for Genetics, Evolution and Environment. The talk seemed to stiir up a lot of interest: the discussions ran on to the next day. |

|
It was clear that younger people are still as infatuated with Nature and Science as ever. And that, of course is the fault of their elders.
The only way that I can see, is to abandon impact factor as a way of judging people. It should have gone years ago,and good people have never used it. They read the papers. Access to research will never be free until we think oi a way to break the hegemony of Nature, Science and a handful of others. Stephen Curry has made some suggestions
Probably it will take action from above. The Wellcome Trust has made a good start. And so has Harvard. We should follow their lead (see also, Stephen Curry’s take on Harvard)
And don’t forget to sign up for the Elsevier boycott. Over 10,000 academics have already signed. Tim Gowers’ initiative took off remarkably.
24 July 2012. I’m reminded by Nature writer, Richard van Noorden (@Richvn) that Nature itself has written at least twice about the iniquity of judging people by impact factors. In 2005 Not-so-deep impact said
"Only 50 out of the roughly 1,800 citable items published in those two years received more than 100 citations in 2004. The great majority of our papers received fewer than 20 citations."
"None of this would really matter very much, were it not for the unhealthy reliance on impact factors by administrators and researchers’ employers worldwide to assess the scientific quality of nations and institutions, and often even to judge individuals."
And, more recently, in Assessing assessment” (2010).
27 April 2014
The brilliant mathematician,Tim Gowers, started a real revolt against old-fashioned publishers who are desperately trying to maintain extortionate profits in a world that has changed entirely. In his 2012 post, Elsevier: my part in its downfall, he declared that he would no longer publish in, or act as referee for, any journal published by Elsevier. Please follow his lead and sign an undertaking to that effect: 14,614 people have already signed.
Gowers has now gone further. He’s made substantial progress in penetrating the wall of secrecy with which predatory publishers (of which Elsevier is not the only example) seek to prevent anyone knowing about the profitable racket they are operating. Even the confidentiality agreements, which they force universities to sign, are themselves confidential.
In a new post, Tim Gowers has provided more shocking facts about the prices paid by universities. Please look at Elsevier journals — some facts. The jaw-dropping 2011 sum of €1.25 million paid by UCL alone, is now already well out-of-date. It’s now £1,381,380. He gives figures for many other Russell Group universities too. He also publishes some of the obstructive letters that he got in the process of trying to get hold of the numbers. It’s a wonderful aspect of the web that it’s easy to shame those who deserve to be shamed.
I very much hope the matter is taken to the Information Commissioner, and that a precedent is set that it’s totally unacceptable to keep secret what a university pays for services.