
Download Lectures on Biostatistics (1971). Corrected and searchable version of Google books edition
Download review of Lectures on Biostatistics (THES, 1973).
placebo
|
“Statistical regression to the mean predicts that patients selected for abnormalcy will, on the average, tend to improve. We argue that most improvements attributed to the placebo effect are actually instances of statistical regression.”
“Thus, we urge caution in interpreting patient improvements as causal effects of our actions and should avoid the conceit of assuming that our personal presence has strong healing powers.” |
In 1955, Henry Beecher published "The Powerful Placebo". I was in my second undergraduate year when it appeared. And for many decades after that I took it literally, They looked at 15 studies and found that an average 35% of them got "satisfactory relief" when given a placebo. This number got embedded in pharmacological folk-lore. He also mentioned that the relief provided by placebo was greatest in patients who were most ill.
Consider the common experiment in which a new treatment is compared with a placebo, in a double-blind randomised controlled trial (RCT). It’s common to call the responses measured in the placebo group the placebo response. But that is very misleading, and here’s why.
The responses seen in the group of patients that are treated with placebo arise from two quite different processes. One is the genuine psychosomatic placebo effect. This effect gives genuine (though small) benefit to the patient. The other contribution comes from the get-better-anyway effect. This is a statistical artefact and it provides no benefit whatsoever to patients. There is now increasing evidence that the latter effect is much bigger than the former.
How can you distinguish between real placebo effects and get-better-anyway effect?
The only way to measure the size of genuine placebo effects is to compare in an RCT the effect of a dummy treatment with the effect of no treatment at all. Most trials don’t have a no-treatment arm, but enough do that estimates can be made. For example, a Cochrane review by Hróbjartsson & Gøtzsche (2010) looked at a wide variety of clinical conditions. Their conclusion was:
“We did not find that placebo interventions have important clinical effects in general. However, in certain settings placebo interventions can influence patient-reported outcomes, especially pain and nausea, though it is difficult to distinguish patient-reported effects of placebo from biased reporting.”
In some cases, the placebo effect is barely there at all. In a non-blind comparison of acupuncture and no acupuncture, the responses were essentially indistinguishable (despite what the authors and the journal said). See "Acupuncturists show that acupuncture doesn’t work, but conclude the opposite"
So the placebo effect, though a real phenomenon, seems to be quite small. In most cases it is so small that it would be barely perceptible to most patients. Most of the reason why so many people think that medicines work when they don’t isn’t a result of the placebo response, but it’s the result of a statistical artefact.
Regression to the mean is a potent source of deception
The get-better-anyway effect has a technical name, regression to the mean. It has been understood since Francis Galton described it in 1886 (see Senn, 2011 for the history). It is a statistical phenomenon, and it can be treated mathematically (see references, below). But when you think about it, it’s simply common sense.
You tend to go for treatment when your condition is bad, and when you are at your worst, then a bit later you’re likely to be better, The great biologist, Peter Medawar comments thus.
|
"If a person is (a) poorly, (b) receives treatment intended to make him better, and (c) gets better, then no power of reasoning known to medical science can convince him that it may not have been the treatment that restored his health"
(Medawar, P.B. (1969:19). The Art of the Soluble: Creativity and originality in science. Penguin Books: Harmondsworth). |
This is illustrated beautifully by measurements made by McGorry et al., (2001). Patients with low back pain recorded their pain (on a 10 point scale) every day for 5 months (they were allowed to take analgesics ad lib).
The results for four patients are shown in their Figure 2. On average they stay fairly constant over five months, but they fluctuate enormously, with different patterns for each patient. Painful episodes that last for 2 to 9 days are interspersed with periods of lower pain or none at all. It is very obvious that if these patients had gone for treatment at the peak of their pain, then a while later they would feel better, even if they were not actually treated. And if they had been treated, the treatment would have been declared a success, despite the fact that the patient derived no benefit whatsoever from it. This entirely artefactual benefit would be the biggest for the patients that fluctuate the most (e.g this in panels a and d of the Figure).
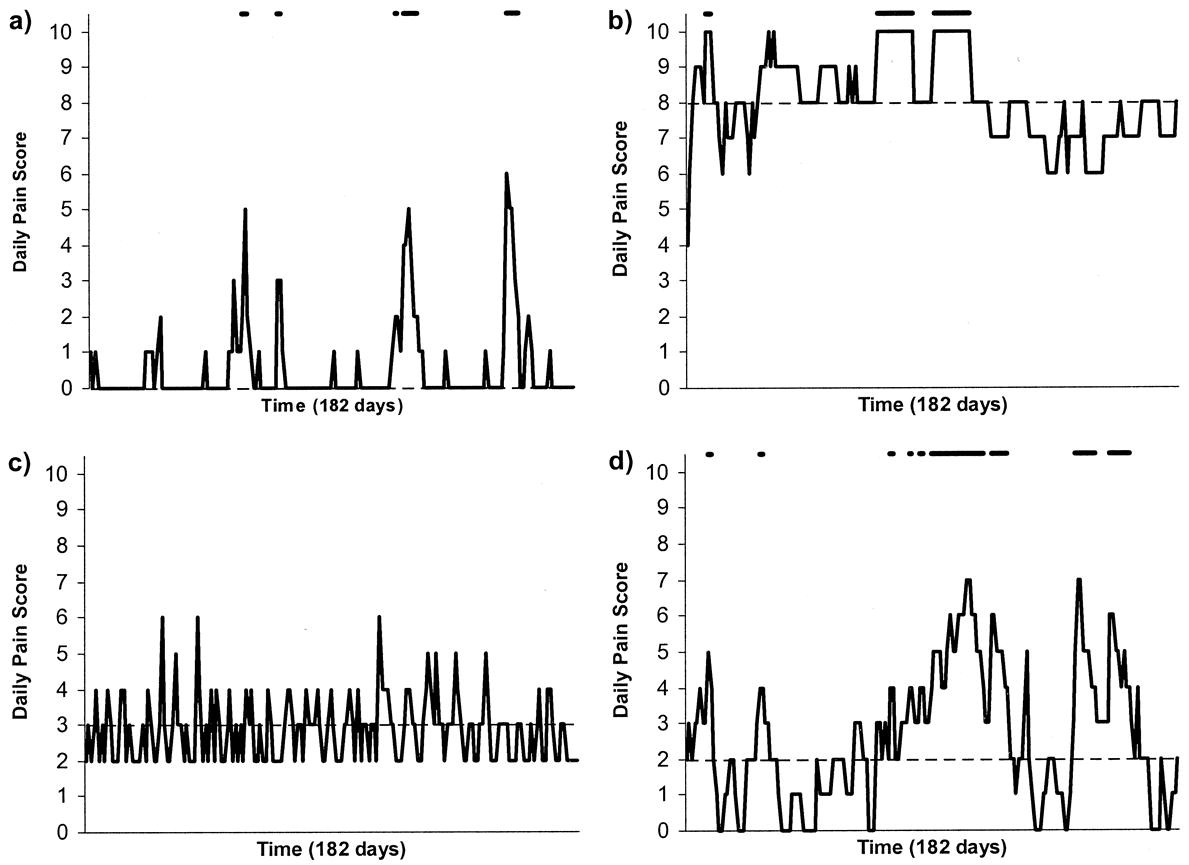
Figure 2 from McGorry et al, 2000. Examples of daily pain scores over a 6-month period for four participants. Note: Dashes of different lengths at the top of a figure designate an episode and its duration.
The effect is illustrated well by an analysis of 118 trials of treatments for non-specific low back pain (NSLBP), by Artus et al., (2010). The time course of pain (rated on a 100 point visual analogue pain scale) is shown in their Figure 2. There is a modest improvement in pain over a few weeks, but this happens regardless of what treatment is given, including no treatment whatsoever.
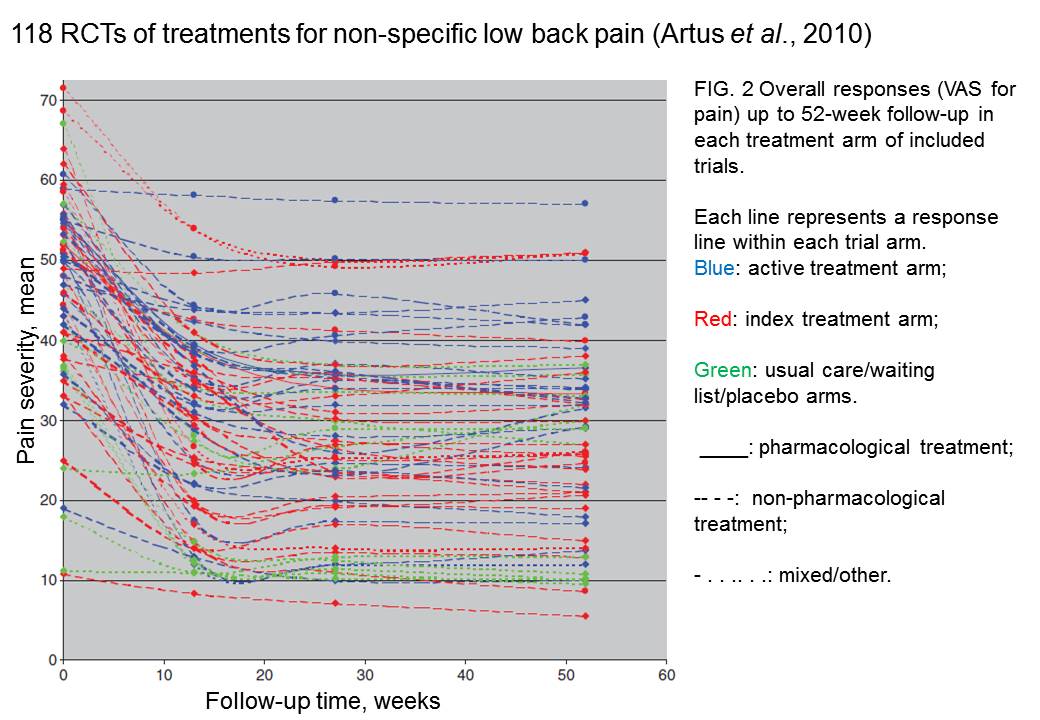
FIG. 2 Overall responses (VAS for pain) up to 52-week follow-up in each treatment arm of included trials. Each line represents a response line within each trial arm. Red: index treatment arm; Blue: active treatment arm; Green: usual care/waiting list/placebo arms. ____: pharmacological treatment; – – – -: non-pharmacological treatment; . . .. . .: mixed/other.
The authors comment
"symptoms seem to improve in a similar pattern in clinical trials following a wide variety of active as well as inactive treatments.", and "The common pattern of responses could, for a large part, be explained by the natural history of NSLBP".
In other words, none of the treatments work.
This paper was brought to my attention through the blog run by the excellent physiotherapist, Neil O’Connell. He comments
"If this finding is supported by future studies it might suggest that we can’t even claim victory through the non-specific effects of our interventions such as care, attention and placebo. People enrolled in trials for back pain may improve whatever you do. This is probably explained by the fact that patients enrol in a trial when their pain is at its worst which raises the murky spectre of regression to the mean and the beautiful phenomenon of natural recovery."
O’Connell has discussed the matter in recent paper, O’Connell (2015), from the point of view of manipulative therapies. That’s an area where there has been resistance to doing proper RCTs, with many people saying that it’s better to look at “real world” outcomes. This usually means that you look at how a patient changes after treatment. The hazards of this procedure are obvious from Artus et al.,Fig 2, above. It maximises the risk of being deceived by regression to the mean. As O’Connell commented
"Within-patient change in outcome might tell us how much an individual’s condition improved, but it does not tell us how much of this improvement was due to treatment."
In order to eliminate this effect it’s essential to do a proper RCT with control and treatment groups tested in parallel. When that’s done the control group shows the same regression to the mean as the treatment group. and any additional response in the latter can confidently attributed to the treatment. Anything short of that is whistling in the wind.
Needless to say, the suboptimal methods are most popular in areas where real effectiveness is small or non-existent. This, sad to say, includes low back pain. It also includes just about every treatment that comes under the heading of alternative medicine. Although these problems have been understood for over a century, it remains true that
|
"It is difficult to get a man to understand something, when his salary depends upon his not understanding it."
Upton Sinclair (1935) |
Responders and non-responders?
One excuse that’s commonly used when a treatment shows only a small effect in proper RCTs is to assert that the treatment actually has a good effect, but only in a subgroup of patients ("responders") while others don’t respond at all ("non-responders"). For example, this argument is often used in studies of anti-depressants and of manipulative therapies. And it’s universal in alternative medicine.
There’s a striking similarity between the narrative used by homeopaths and those who are struggling to treat depression. The pill may not work for many weeks. If the first sort of pill doesn’t work try another sort. You may get worse before you get better. One is reminded, inexorably, of Voltaire’s aphorism "The art of medicine consists in amusing the patient while nature cures the disease".
There is only a handful of cases in which a clear distinction can be made between responders and non-responders. Most often what’s observed is a smear of different responses to the same treatment -and the greater the variability, the greater is the chance of being deceived by regression to the mean.
For example, Thase et al., (2011) looked at responses to escitalopram, an SSRI antidepressant. They attempted to divide patients into responders and non-responders. An example (Fig 1a in their paper) is shown.
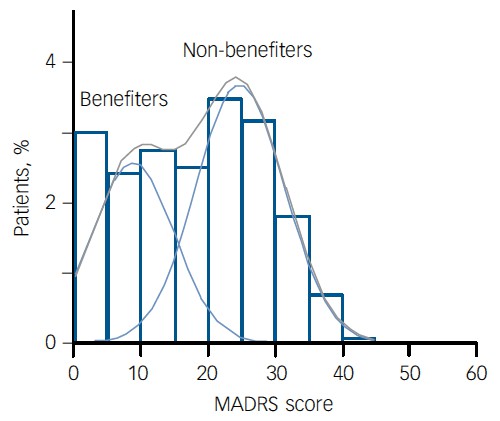
The evidence for such a bimodal distribution is certainly very far from obvious. The observations are just smeared out. Nonetheless, the authors conclude
"Our findings indicate that what appears to be a modest effect in the grouped data – on the boundary of clinical significance, as suggested above – is actually a very large effect for a subset of patients who benefited more from escitalopram than from placebo treatment. "
I guess that interpretation could be right, but it seems more likely to be a marketing tool. Before you read the paper, check the authors’ conflicts of interest.
The bottom line is that analyses that divide patients into responders and non-responders are reliable only if that can be done before the trial starts. Retrospective analyses are unreliable and unconvincing.
Some more reading
Senn, 2011 provides an excellent introduction (and some interesting history). The subtitle is
"Here Stephen Senn examines one of Galton’s most important statistical legacies – one that is at once so trivial that it is blindingly obvious, and so deep that many scientists spend their whole career being fooled by it."
The examples in this paper are extended in Senn (2009), “Three things that every medical writer should know about statistics”. The three things are regression to the mean, the error of the transposed conditional and individual response.
You can read slightly more technical accounts of regression to the mean in McDonald & Mazzuca (1983) "How much of the placebo effect is statistical regression" (two quotations from this paper opened this post), and in Stephen Senn (2015) "Mastering variation: variance components and personalised medicine". In 1988 Senn published some corrections to the maths in McDonald (1983).
The trials that were used by Hróbjartsson & Gøtzsche (2010) to investigate the comparison between placebo and no treatment were looked at again by Howick et al., (2013), who found that in many of them the difference between treatment and placebo was also small. Most of the treatments did not work very well.
Regression to the mean is not just a medical deceiver: it’s everywhere
Although this post has concentrated on deception in medicine, it’s worth noting that the phenomenon of regression to the mean can cause wrong inferences in almost any area where you look at change from baseline. A classical example concern concerns the effectiveness of speed cameras. They tend to be installed after a spate of accidents, and if the accident rate is particularly high in one year it is likely to be lower the next year, regardless of whether a camera had been installed or not. To find the true reduction in accidents caused by installation of speed cameras, you would need to choose several similar sites and allocate them at random to have a camera or no camera. As in clinical trials. looking at the change from baseline can be very deceptive.
Statistical postscript
Lastly, remember that it you avoid all of these hazards of interpretation, and your test of significance gives P = 0.047. that does not mean you have discovered something. There is still a risk of at least 30% that your ‘positive’ result is a false positive. This is explained in Colquhoun (2014),"An investigation of the false discovery rate and the misinterpretation of p-values". I’ve suggested that one way to solve this problem is to use different words to describe P values: something like this.
|
P > 0.05 very weak evidence
P = 0.05 weak evidence: worth another look P = 0.01 moderate evidence for a real effect P = 0.001 strong evidence for real effect |
But notice that if your hypothesis is implausible, even these criteria are too weak. For example, if the treatment and placebo are identical (as would be the case if the treatment were a homeopathic pill) then it follows that 100% of positive tests are false positives.
Follow-up
12 December 2015
It’s worth mentioning that the question of responders versus non-responders is closely-related to the classical topic of bioassays that use quantal responses. In that field it was assumed that each participant had an individual effective dose (IED). That’s reasonable for the old-fashioned LD50 toxicity test: every animal will die after a sufficiently big dose. It’s less obviously right for ED50 (effective dose in 50% of individuals). The distribution of IEDs is critical, but it has very rarely been determined. The cumulative form of this distribution is what determines the shape of the dose-response curve for fraction of responders as a function of dose. Linearisation of this curve, by means of the probit transformation used to be a staple of biological assay. This topic is discussed in Chapter 10 of Lectures on Biostatistics. And you can read some of the history on my blog about Some pharmacological history: an exam from 1959.
|
Synexus is "The world’s largest multi-national company entirely focused on the recruitment and running of clinical trials company that runs clinical trials and screening programmes". |
|
I should say at the outset that I’m deeply impressed by our local GP practice. I can’t imagine a better GP than mine; he has the ideal mix of knowledge and empathy. I do, however, worry about the fragmentisation of the NHS and its creeping privatisation.
I came across Synexus because my wife had a letter (on our GP practice letterhead) inviting her to go for osteoporosis screening, and possibly to "take part in a study". Download the letter.
Notice that the form gives no idea of what the "study" might be. Notice also, more seriously, the small print on the second page of the form. Here it is in normal size print.
"If you contact Synexus and/or return the attached tear-off slip Synexus may, with your consent, use the data you provide for the purposes of informing you of the study, of medical products and processes that might be of interest to you. Your information will be held by, and access to it limited to, Synexus Ltd and/or companies within the Synexus group of companies and/or third parties acting on their behalf"
You are invited, in near-illegible small print, to allow all your medical data to be handed over to Synexus [see comment, below], and an unspecified number of other companies and third parties. It also gives the company permission to "use the data you provide for the purposes of informing you. . . of medical products and processes that might be of interest to you". This appears to mean that in the future you’ll be pestered with mailings that bypass your GP and advertise (private?) screening etc. For the purposes of screening there should be no need to hand over any data whatsoever (and the practice manager ensures me that they don’t).
My wife asked my advice about whether she should sign up for "the study" if invited to do so, so I asked the GP practice what the trial was about. Rather to my surprise, they didn’t know. Neither did Hertfordshire NHS. So I asked the National Osteoporosis Society, and they didn’t know either. After several emails and a phone call, I eventually got the details from Synexus.
I have two concerns about this. One is the argument that’s been raging about the value of indiscrimate screening, The case against it has been put perfectly in Margaret McCartney’s recent book, The Patient Paradox. There’s a good case that too much money is spent on people who are well, and not enough on those who are ill. Of course prevention is better than cure. The problem is that in many cases the screening tests aren’t accurate enough, so many people get diagnosed and treated when they are not actually ill.
On top of that, there is now a serious worry about screening tests promoted by private companies, for profit. Lifeline has been criticised, for good reasons. The men’s health charity, Movember, promotes PSA screening for prostate cancer, one of the most unreliable tests in existence. There is now a web site that collates evidence about private health screening. Many of the tests are available on the NHS, and the NHS advice about them is being re-written so that it gives information about risks as well as benefits.
The NHS advice on screening for osteoporosis is still ambiguous. The evidence for benefit of screening at age 60 is not clear.
The main question, though, is this. If my wife were offered an opportunity to "take part in a study", should she say yes, or no? My first inclination was to say yes. Clinical trials are the only way to find out whether treatments work or not. If people don’t volunteer for trials, we’ll never know. But before saying yes, one would want to know that the trial was organised properly, so that it could answer a relevant question. That’s why I was surprised when I found it so hard to discover the details. Nobody seemed to know even where the trial was registered. It’s no use searching trial registers for "Synexus": you need to know who is paying for it.
Eventually Dr John Robinson of Synexus turned out to be very helpful. The protocol number is 20070337 with a EudraCT number 2011-001456-11. The trial is registered at ClinicalTrails.gov and it has ethical approval. It’s a trial of a new osteoporosis treatment made by Amgen, AMG 785. It’s a monoclonal antibody against sclerostin, a protein that inhibits bone formation. It sounds like a good idea, but we won’t know how well it works until it’s been tested. The allocation of patients to AMG 785 or placebo is randomised and double blind. The patient Information sheet for participants looks pretty good to me.
Nevertheless, I have some reservations about the trial. First, its organisation is odd. “After taking AMG 785 or placebo for one year, all study participants will be taking denosumab for the following year”. Denusomab is another product of the same company, Amgen. It has already been approved by NICE. When I asked Dr Robinson why this arrangement had been chosen, this is what he said.
"Previous studies have shown that the maximal benefit on bone density is seen after 12 months and that treatment after this period shows a lower increase, it is for this reason treatment with AMG 785 is for 12 months in this study.
Other studies have also shown benefit in further improving and maintaining the increase in bone density and reducing fracture risk by subsequently treating patients with Alendronate after 12 months of AMG 785. This study is investigating whether similar or better findings occur with denosumab."
This does not make any sense to me. If the object is to compare AMG 785 with denusomab, they should be compared side by side, not sequentially. That brings us straight to the main problem with the trial design. It asks the wrong question. What the doctor needs to know is whether AMG 785 is more effective than existing treatments, not whether it is better than placebo. When I asked Dr Robinson about this, he said
"To quote from the protocol: A placebo-controlled study was chosen because it permits a minimally confounded demonstration of efficacy and safety of AMG 785 in the treatment of PMO. Using an active control such as a bisphosphonate means that more patients have to be enrolled to show benefit from AMG 785. The study already plans to enrol 6000 women. Increasing this number would add to the time required to complete the study. In addition the use of a placebo control is also within regulatory guidelines. "
What this means, in plain English, is that they are expecting a rather small difference between AMG 785 and existing treatments. It would take a very large number of patients to show this difference. If the difference is indeed small, it would be hard to justify the (doubtless eye-watering) cost of AMG 795 (denusomab costs £185.00 per dose). Testing a new drug against placebo, or against a low dose of something not very effective, is one of the stratagems listed in Chapter 4, Bad trials, in Ben Goldacre’s Bad Pharma. It makes the new drug look good, but it asks the wrong question.
The National Osteoporosis Society should be an organisation to which patients could turn to for advice in cases like this. In this case they were not helpful. They didn’t know much about the trial. I hope that this is not related to the fact that they get a lot of funding from Synexus. I noticed too that one of their advisors is the infamous Professor Richard Eastell, who admitted in print to lying in a paper, about a drug for osteoporosis made by Proctor & Gamble. It’s getting quite hard to find a medical charity that isn’t in the pocket of Big Pharma. or quacks (or even occasionally, both).
Conclusion. The trial asks the wrong question. On those grounds alone, I think that my advice would be not to volunteer for the trial.
Follow-up
I should have mentioned an interesting and relevant Cochrane review, New treatments compared to established treatments in randomized trials (2012), The authors’ conclusions are as follows.
“Society can expect that slightly more than half of new experimental treatments will prove to be better than established treatments when tested in RCTs, but few will be substantially better. This is an important finding for patients (as they contemplate participation in RCTs), researchers (as they plan design of the new trials), and funders (as they assess the ’return on investment’).”
15 May 2013. As noted in the comments, Synexus has been censured by the Advertising Standards Authority, because the ASA judged that they did not give sufficient prominence to the fact that there advertising of free screening was actually a way to recruit people into clinical trials.