Download Lectures on Biostatistics (1971). Corrected and searchable version of Google books edition
Download review of Lectures on Biostatistics (THES, 1973).
randomisation
Chalkdust is a magazine published by students of maths from UCL Mathematics department. Judging by its first issue, it’s an excellent vehicle for popularisation of maths. I have a piece in the second issue
You can view the whole second issue on line, or download a pdf of the whole issue. Or a pdf of my bit only: On the Perils of P values.
The piece started out as another exposition of the interpretation of P values, but the whole of the first part turned into an explanation of the principles of randomisation tests. It beats me why anybody still does a Student’s t test. The idea of randomisation tests is very old. They are as powerful as t tests when the assumptions of the latter are fulfilled but a lot better when the assumptions are wrong (in the jargon, they are uniformly-most-powerful tests).
Not only that, but you need no mathematics to do a randomisation test, whereas you need a good deal of mathematics to follow Student’s 1908 paper. And the randomisation test makes transparently clear that random allocation of treatments is a basic and essential assumption that’s necessary for the the validity of any test of statistical significance.
I made a short video that explains the principles behind the randomisation tests, to go with the printed article (a bit of animation always helps).
When I first came across the principals of randomisation tests, i was entranced by the simplicity of the idea. Chapters 6 – 9 of my old textbook were written to popularise them. You can find much more detail there.
In fact it’s only towards the end that I reiterate the idea that P values don’t answer the question that experimenters want to ask, namely:- if I claim I have made a discovery because P is small, what’s the chance that I’ll be wrong?
If you want the full story on that, read my paper. The story it tells is not very original, but it still isn’t known to most experimenters (because most statisticians still don’t teach it on elementary courses). The paper must have struck a chord because it’s had over 80,000 full text views and more than 10,000 pdf downloads. It reached an altmetric score of 975 (since when it has been mysteriously declining). That’s gratifying, but it is also a condemnation of the use of metrics. The paper is not original and it’s quite simple, yet it’s had far more "impact" than anything to do with my real work.
If you want simpler versions than the full paper, try this blog (part 1 and part 2), or the Youtube video about misinterpretation of P values.
The R code for doing 2-sample randomisation tests
You can download a pdf file that describes the two R scripts. There are two different R programs.
One re-samples randomly a specified number of times (the default is 100,000 times, but you can do any number). Download two_sample_rantest.R
The other uses every possible sample -in the case of the two samples of 10 observations,it gives the distribution for all 184,756 ways of selecting 10 observations from 20. Download 2-sample-rantest-exact.R
The launch party
Today the people who organise Chalkdust magazine held a party in the mathematics department at UCL. The editorial director is a graduate student in maths, Rafael Prieto Curiel. He was, at one time in the Mexican police force (he said he’d suffered more crime in London than in Mexico City). He, and the rest of the team, are deeply impressive. They’ve done a terrific job. Support them.

The party cakes

Rafael Prieto doing the introduction

Rafael Prieto doing the introduction

Rafael Prieto and me
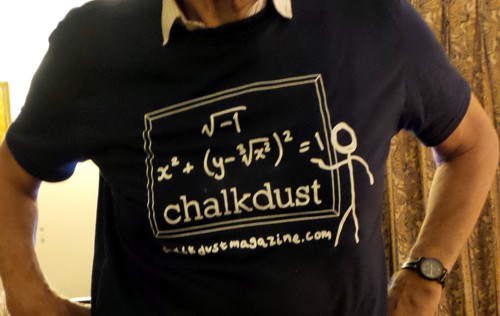
I got the T shirt
Decoding the T shirt
The top line is "I" because that’s the usual symbol for the square root of -1.
|
The second line is one of many equations that describe a heart shape. It can be plotted by calculating a matrix of values of the left hand side for a range of values of x and y. Then plot the contour for a values x and y for which the left hand side is equal to 1. Download R script for this. (Method suggested by Rafael Prieto Curiel.) |
 |
Follow-up
5 November 2015
The Mann-Whitney test
I was stimulated to write this follow-up because yesterday I was asked by a friend to comment on the fact that five different tests all gave identical P values, P = 0.0079. The paper in question was in Science magazine (see Fig. 1), so it wouldn’t surprise me if the statistics were done badly, but in this case there is an innocent explanation.
The Chalkdust article, and the video, are about randomisation tests done using the original observed numbers, so look at them before reading on. There is a more detailed explanation in Chapter 9 of Lectures on Biostatistics. Before it became feasible to do this sort of test, there was a simpler, and less efficient, version in which the observations were ranked in ascending order, and the observed values were replaced by their ranks. This was known as the Mann Whitney test. It had the virtue that because all the ‘observations’ were now integers, the number of possible results of resampling was limited so it was possible to construct tables to allow one to get a rough P value. Of course, replacing observations by their ranks throws away some information, and now that we have computers there is no need to use a Mann-Whitney test ever. But that’s what was used in this paper.
In the paper (Fig 1) comparisons are made between two groups (assumed to be independent) with 5 observations in each group. The 10 observations are just the ranks, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10.
To do the randomisation test we select 5 of these numbers at random for sample A, and the other 5 are sample B. (Of course this supposes that the treatments were applied randomly in the real experiment, which is unlikely to be true.) In fact there are only 10!/(5!.5!) = 252 possible ways to select a sample of 5 from 10, so it’s easy to list all of them. In the case where there is no overlap between the groups, one group will contain the smallest observations (ranks 1, 2, 3, 4, 5, and the other group will contain the highest observations, ranks 6, 7, 8, 9, 10.
In this case, the sum of the ‘observations’ in group A is 15, and the sum for group B is 40.These add to the sum of the first 10 integers, 10.(10+1)/2 = 55. The mean (which corresponds to a difference between means of zero) is 55/2 = 27.5.
There are two ways of getting an allocation as extreme as this (first group low, as above, or second group low, the other tail of the distribution). The two tailed P value is therefore 2/252 = 0.0079. This will be the result whenever the two groups don’t overlap, regardless of the numerical values of the observations. It’s the smallest P value the test can produce with 5 observations in each group.
The whole randomisation distribution looks like this
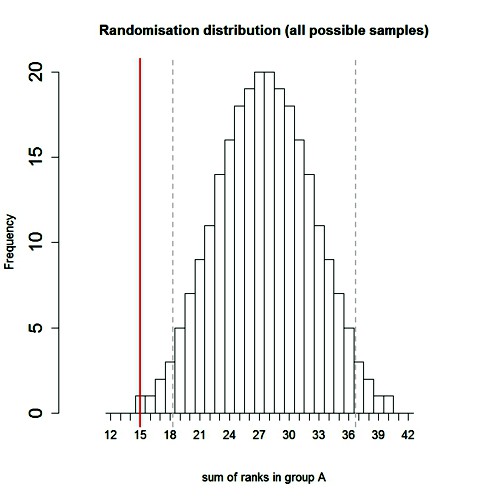
In this case, the abscissa is the sum of the ranks in sample A, rather than the difference between means for the two groups (the latter is easily calculated from the former). The red line shows the observed value, 15. There is only one way to get a total of 15 for group A: it must contain the lowest 5 ranks (group A = 1, 2, 3, 4, 5). There is also only one way to get a total of 16 (group A = 1, 2, 3, 4, 6),and there are two ways of getting a total of 17 (group A = 1, 2, 3, 4, 7, or 1, 2, 3, 5, 6), But there are 20 different ways of getting a sum of 27 or 28 (which straddle the mean, 27.5). The printout (.txt file) from the R program that was used to generate the distribution is as follows.
|
Randomisation test: exact calculation all possible samples INPUTS: exact calculation: all possible samples OUTPUTS Result of t test
|
Some problems. Figure 1 alone shows 16 two-sample comparisons, but no correction for multiple comparisons seems to have been made. A crude Bonferroni correction would require replacement of a P = 0.05 threshold with P = 0.05/16 = 0.003. None of the 5 tests that gave P = 0.0079 reaches this level (of course the whole idea of a threshold level is absurd anyway).
Furthermore, even a single test that gave P = 0.0079 would be expected to have a false positive rate of around 10 percent
One of my scientific heroes is Bernard Katz. The closing words of his inaugural lecture, as professor of biophysics at UCL, hang on the wall of my office as a salutory reminder to refrain from talking about ‘how the brain works’. After speaking about his discoveries about synaptic transmission, he ended thus.
|
"My time is up and very glad I am, because I have been leading myself right up to a domain on which I should not dare to trespass, not even in an Inaugural Lecture. This domain contains the awkward problems of mind and matter about which so much has been talked and so little can be said, and having told you of my pedestrian disposition, I hope you will give me leave to stop at this point and not to hazard any further guesses." |
 Drawing ©Jenny Hersson-Ringskog |
The question of what to eat for good health is truly a topic about "which so much has been talked and so little can be said"
That was emphasized yet again by an editorial in the British Medical Journal written by my favourite epidemiologist. John Ioannidis. He has been at the forefront of debunking hype. Its title is “Implausible results in human nutrition research” (BMJ, 2013;347:f6698.
Get pdf).
The gist is given by the memorable statement
"Almost every single nutrient imaginable has peer reviewed publications associating it with almost any outcome."
and the subtitle
“Definitive solutions won’t come from another million observational papers or small randomized trials“.
Being a bit obsessive about causality, this paper is music to my ears. The problem of causality was understood perfectly by Samuel Johnson, in 1756, and he was a lexicographer, not a scientist. Yet it’s widely ignored by epidemiologists.

The problem of causality is often mentioned in the introduction to papers that describe survey data, yet by the end of the paper, it’s usually forgotten, and public health advice is issued.
Ioannidis’ editorial vindicates my own views, as an amateur epidemiologist, on the results of the endless surveys of diet and health.
- Diet and health. What can you believe: or does bacon kill you (2009) in which I look at the World Cancer Research Fund’s evidence for causality (next to none in my opinion). Through this I got to know Gary Taubes, whose explanation of causality in the New York Times is the best popular account I’ve ever seen.
- How big is the risk from eating red meat now: an update (2012) This was based on the WCRF update – the risk was roughly halved though it didn’t say that in the press release.
- Another update. Red meat doesn’t kill you, but the spin is fascinating (2013). Update after the EPIC results in which the risk essentially vanished: good news which you could find only by digging into Table 3.
There is nothing new about the problem. It’s been written about many times. Young & Karr (Significance, 8, 116 – 120, 2011: get pdf) said "Any claim coming from an observational study is most likely to be wrong". Out of 52 claims made in 12 observational studies, not a single one was confirmed when tested by randomised controlled trials.
Another article cited by Ioannidis, "Myths, Presumptions, and Facts about Obesity" (Casazza et al , NEJM, 2013), debunks many myths, but the list of conflicts of interests declared by the authors is truly horrendous (and at least one of their conclusions has been challenged, albeit by people with funding from Kellogg’s). The frequent conflicts of interest in nutrition research make a bad situation even worse.
The quotation in bold type continues thus.
"On 25 October 2013, PubMed listed 291 papers with the keywords “coffee OR caffeine” and 741 with “soy,” many of which referred to associations. In this literature of epidemic proportions, how many results are correct? Many findings are entirely implausible. Relative risks that suggest we can halve the burden of cancer with just a couple of servings a day of a single nutrient still circulate widely in peer reviewed journals.
However, on the basis of dozens of randomized trials, single nutrients are unlikely to have relative risks less than 0.90 for major clinical outcomes when extreme tertiles of population intake are compared—most are greater than 0.95. For overall mortality, relative risks are typically greater than 0.995, if not entirely null. The respective absolute risk differences would be trivial. Observational studies and even randomized trials of single nutrients seem hopeless, with rare exceptions. Even minimal confounding or other biases create noise that exceeds any genuine effect. Big datasets just confer spurious precision status to noise."
And, later,
"According to the latest burden of disease study, 26% of deaths and 14% of disability adjusted life years in the United States are attributed to dietary risk factors, even without counting the impact of obesity. No other risk factor comes anywhere close to diet in these calculations (not even tobacco and physical inactivity). I suspect this is yet another implausible result. It builds on risk estimates from the same data of largely implausible nutritional studies discussed above. Moreover, socioeconomic factors are not considered at all, although they may be at the root of health problems. Poor diet may partly be a correlate or one of several paths through which social factors operate on health."
Another field that is notorious for producing false positives, wirh false attribution of causality, is the detection of biomarkers. A critical discussion can be found in the paper by Broadhurst & Kell (2006), "False discoveries in metabolomics and related experiments".
"Since the early days of transcriptome analysis (Golub et al., 1999), many workers have looked to detect different gene expression in cancerous versus normal tissues. Partly because of the expense of transcriptomics (and the inherent noise in such data (Schena, 2000; Tu et al., 2002; Cui and Churchill, 2003; Liang and Kelemen, 2006)), the numbers of samples and their replicates is often small while the number of candidate genes is typically in the thousands. Given the above, there is clearly a great danger that most of these will not in practice withstand scrutiny on deeper analysis (despite the ease with which one can create beautiful heat maps and any number of ‘just-so’ stories to explain the biological relevance of anything that is found in preliminary studies!). This turns out to be the case, and we review a recent analysis (Ein-Dor et al., 2006) of a variety of such studies."
The fields of metabolomics, proteomics and transcriptomics are plagued by statistical problems (as well as being saddled with ghastly pretentious names).
What’s to be done?
Barker Bausell, in his demolition of research on acupuncture, said:
[Page39] “But why should nonscientists care one iota about something as esoteric as causal inference? I believe that the answer to this question is because the making of causal inferences is part of our job description as Homo Sapiens.”
The problem, of course, is that humans are very good at attributing causality when it does not exist. That has led to confusion between correlation and cause on an industrial scale, not least in attempts to work out the effects of diet on health.
More than in any other field it is hard to do the RCTs that could, in principle, sort out the problem. It’s hard to allocate people at random to different diets, and even harder to make people stick to those diets for the many years that are needed.
We can probably say by now that no individual food carries a large risk, or affords very much protection. The fact that we are looking for quite small effects means that even when RCTs are possible huge samples will be needed to get clear answers. Most RCTs are too short, and too small (under-powered) and that leads to overestimation of the size of effects.
That’s a problem that plagues experimental pyschology too, and has led to a much-discussed crisis in reproducibility.
"Supplements" of one sort and another are ubiquitous in sports. Nobody knows whether they work, and the margin between winning and losing is so tiny that it’s very doubtful whether we ever will know. We can expect irresponsible claims to continue unabated.
The best thing that can be done in the short term is to stop doing large observational studies altogether. It’s now clear that inferences made from them are likely to be wrong. And, sad to say, we need to view with great skepticism anything that is funded by the food industry. And make a start on large RCTs whenever that is possible. Perhaps the hardest goal of all is to end the "publish or perish" culture which does so much to prevent the sort of long term experiments which would give the information we want.
Ioannidis’ article ends with the statement
"I am co-investigator in a randomized trial of a low carbohydrate versus low fat diet that is funded by the US National Institutes of Health and the non-profit Nutrition Science Initiative."
It seems he is putting his money where his mouth is.
Until we have the results, we shall continue to be bombarded with conflicting claims made by people who are doing their best with flawed methods, as well as by those trying to sell fad diets. Don’t believe them. The famous "5-a-day" advice that we are constantly bombarded with does no harm, but it has no sound basis.
As far as I can guess, the only sound advice about healthy eating for most people is
- don’t eat too much
- don’t eat all the same thing
You can’t make much money out of that advice.
No doubt that is why you don’t hear it very often.
Follow-up
Two relevant papers that show the unreliability of observational studies,
"Nearly 80,000 observational studies were published in the decade 1990–2000 (Naik 2012). In the following decade, the number of studies grew to more than 260,000". Madigan et al. (2014)
“. . . the majority of observational studies would declare statistical significance when no effect is present” Schuemie et al., (2012)
20 March 2014
On 20 March 2014, I gave a talk on this topic at the Cambridge Science Festival (more here). After the event my host, Yvonne Noblis, sent me some (doubtless cherry-picked) feedback she’d had about the talk.
I have in the past, taken an occasional interest in the philosophy of science. But in a lifetime doing science, I have hardly ever heard a scientist mention the subject. It is, on the whole, a subject that is of interest only to philosophers.
|
It’s true that some philosophers have had interesting things to say about the nature of inductive inference, but during the 20th century the real advances in that area came from statisticians, not from philosophers. So I long since decided that it would be more profitable to spend my time trying to understand R.A Fisher, rather than read even Karl Popper. It is harder work to do that, but it seemed the way to go.
|
 |
This post is based on the last part of chapter titled “In Praise of Randomisation. The importance of causality in medicine and its subversion by philosophers of science“. A talk was given at the meeting at the British Academy in December 2007, and the book will be launched on November 28th 2011 (good job it wasn’t essential for my CV with delays like that). The book is published by OUP for the British Academy, under the title Evidence, Inference and Enquiry (edited by Philip Dawid, William Twining, and Mimi Vasilaki, 504 pages, £85.00). The bulk of my contribution has already appeared here, in May 2009, under the heading Diet and health. What can you believe: or does bacon kill you?. It is one of the posts that has given me the most satisfaction, if only because Ben Goldacre seemed to like it, and he has done more than anyone to explain the critical importance of randomisation for assessing treatments and for assessing social interventions.
Having long since decided that it was Fisher, rather than philosophers, who had the answers to my questions, why bother to write about philosophers at all? It was precipitated by joining the London Evidence Group. Through that group I became aware that there is a group of philosophers of science who could, if anyone took any notice of them, do real harm to research. It seems surprising that the value of randomisation should still be disputed at this stage, and of course it is not disputed by anybody in the business. It was thoroughly established after the start of small sample statistics at the beginning of the 20th century. Fisher’s work on randomisation and the likelihood principle put inference on a firm footing by the mid-1930s. His popular book, The Design of Experiments made the importance of randomisation clear to a wide audience, partly via his famous example of the lady tasting tea. The development of randomisation tests made it transparently clear (perhaps I should do a blog post on their beauty). By the 1950s. the message got through to medicine, in large part through Austin Bradford Hill.
Despite this, there is a body of philosophers who dispute it. And of course it is disputed by almost all practitioners of alternative medicine (because their treatments usually fail the tests). Here are some examples.
“Why there’s no cause to randomise” is the rather surprising title of a report by Worrall (2004; see also Worral, 2010), from the London School of Economics. The conclusion of this paper is
“don’t believe the bad press that ‘observational studies’ or ‘historically controlled trials’ get – so long as they are properly done (that is, serious thought has gone in to the possibility of alternative explanations of the outcome), then there is no reason to think of them as any less compelling than an RCT.”
In my view this conclusion is seriously, and dangerously, wrong –it ignores the enormous difficulty of getting evidence for causality in real life, and it ignores the fact that historically controlled trials have very often given misleading results in the past, as illustrated by the diet problem.. Worrall’s fellow philosopher, Nancy Cartwright (Are RCTs the Gold Standard?, 2007), has made arguments that in some ways resemble those of Worrall.
Many words are spent on defining causality but, at least in the clinical setting the meaning is perfectly simple. If the association between eating bacon and colorectal cancer is causal then if you stop eating bacon you’ll reduce the risk of cancer. If the relationship is not causal then if you stop eating bacon it won’t help at all. No amount of Worrall’s “serious thought” will substitute for the real evidence for causality that can come only from an RCT: Worrall seems to claim that sufficient brain power can fill in missing bits of information. It can’t. I’m reminded inexorably of the definition of “Clinical experience. Making the same mistakes with increasing confidence over an impressive number of years.” In Michael O’Donnell’s A Sceptic’s Medical Dictionary.
At the other philosophical extreme, there are still a few remnants of post-modernist rhetoric to be found in obscure corners of the literature. Two extreme examples are the papers by Holmes et al. and by Christine Barry. Apart from the fact that they weren’t spoofs, both of these papers bear a close resemblance to Alan Sokal’s famous spoof paper, Transgressing the boundaries: towards a transformative hermeneutics of quantum gravity (Sokal, 1996). The acceptance of this spoof by a journal, Social Text, and the subsequent book, Intellectual Impostures, by Sokal & Bricmont (Sokal & Bricmont, 1998), exposed the astonishing intellectual fraud if postmodernism (for those for whom it was not already obvious). A couple of quotations will serve to give a taste of the amazing material that can appear in peer-reviewed journals. Barry (2006) wrote
“I wish to problematise the call from within biomedicine for more evidence of alternative medicine’s effectiveness via the medium of the randomised clinical trial (RCT).”
“Ethnographic research in alternative medicine is coming to be used politically as a challenge to the hegemony of a scientific biomedical construction of evidence.”
“The science of biomedicine was perceived as old fashioned and rejected in favour of the quantum and chaos theories of modern physics.”
“In this paper, I have deconstructed the powerful notion of evidence within biomedicine, . . .”
The aim of this paper, in my view, is not obtain some subtle insight into the process of inference but to try to give some credibility to snake-oil salesmen who peddle quack cures. The latter at least make their unjustified claims in plain English.
The similar paper by Holmes, Murray, Perron & Rail (Holmes et al., 2006) is even more bizarre.
“Objective The philosophical work of Deleuze and Guattari proves to be useful in showing how health sciences are colonised (territorialised) by an all-encompassing scientific research paradigm “that of post-positivism ” but also and foremost in showing the process by which a dominant ideology comes to exclude alternative forms of knowledge, therefore acting as a fascist structure. “,
It uses the word fascism, or some derivative thereof, 26 times. And Holmes, Perron & Rail (Murray et al., 2007)) end a similar tirade with
“We shall continue to transgress the diktats of State Science.”
It may be asked why it is even worth spending time on these remnants of the utterly discredited postmodernist movement. One reason is that rather less extreme examples of similar thinking still exist in some philosophical circles.
Take, for example, the views expressed papers such as Miles, Polychronis and Grey (2006), Miles & Loughlin (2006), Miles, Loughlin & Polychronis (Miles et al., 2007) and Loughlin (2007).. These papers form part of the authors’ campaign against evidence-based medicine, which they seem to regard as some sort of ideological crusade, or government conspiracy. Bizarrely they seem to think that evidence-based medicine has something in common with the managerial culture that has been the bane of not only medicine but of almost every occupation (and which is noted particularly for its disregard for evidence). Although couched in the sort of pretentious language favoured by postmodernists, in fact it ends up defending the most simple-minded forms of quackery. Unlike Barry (2006), they don’t mention alternative medicine explicitly, but the agenda is clear from their attacks on Ben Goldacre. For example, Miles, Loughlin & Polychronis (Miles et al., 2007) say this.
“Loughlin identifies Goldacre [2006] as a particularly luminous example of a commentator who is able not only to combine audacity with outrage, but who in a very real way succeeds in manufacturing a sense of having been personally offended by the article in question. Such moralistic posturing acts as a defence mechanism to protect cherished assumptions from rational scrutiny and indeed to enable adherents to appropriate the ‘moral high ground’, as well as the language of ‘reason’ and ‘science’ as the exclusive property of their own favoured approaches. Loughlin brings out the Orwellian nature of this manoeuvre and identifies a significant implication.”
If Goldacre and others really are engaged in posturing then their primary offence, at least according to the Sartrean perspective adopted by Murray et al. is not primarily intellectual, but rather it is moral. Far from there being a moral requirement to ‘bend a knee’ at the EBM altar, to do so is to violate one’s primary duty as an autonomous being.”
This ferocious attack seems to have been triggered because Goldacre has explained in simple words what constitutes evidence and what doesn’t. He has explained in a simple way how to do a proper randomised controlled trial of homeopathy. And he he dismantled a fraudulent Qlink pendant, purported to shield you from electromagnetic radiation but which turned out to have no functional components (Goldacre, 2007). This is described as being “Orwellian”, a description that seems to me to be downright bizarre.
In fact, when faced with real-life examples of what happens when you ignore evidence, those who write theoretical papers that are critical about evidence-based medicine may behave perfectly sensibly. Although Andrew Miles edits a journal, (Journal of Evaluation in Clinical Practice), that has been critical of EBM for years. Yet when faced with a course in alternative medicine run by people who can only be described as quacks, he rapidly shut down the course (A full account has appeared on this blog).
It is hard to decide whether the language used in these papers is Marxist or neoconservative libertarian. Whatever it is, it clearly isn’t science. It may seem odd that postmodernists (who believe nothing) end up as allies of quacks (who’ll believe anything). The relationship has been explained with customary clarity by Alan Sokal, in his essay Pseudoscience and Postmodernism: Antagonists or Fellow-Travelers? (Sokal, 2006).
Conclusions
Of course RCTs are not the only way to get knowledge. Often they have not been done, and sometimes it is hard to imagine how they could be done (though not nearly as often as some people would like to say).
It is true that RCTs tell you only about an average effect in a large population. But the same is true of observational epidemiology. That limitation is nothing to do with randomisation, it is a result of the crude and inadequate way in which diseases are classified (as discussed above). It is also true that randomisation doesn’t guarantee lack of bias in an individual case, but only in the long run. But it is the best that can be done. The fact remains that randomization is the only way to be sure of causality, and making mistakes about causality can harm patients, as it did in the case of HRT.
Raymond Tallis (1999), in his review of Sokal & Bricmont, summed it up nicely
“Academics intending to continue as postmodern theorists in the interdisciplinary humanities after S & B should first read Intellectual Impostures and ask themselves whether adding to the quantity of confusion and untruth in the world is a good use of the gift of life or an ethical way to earn a living. After S & B, they may feel less comfortable with the glamorous life that can be forged in the wake of the founding charlatans of postmodern Theory. Alternatively, they might follow my friend Roger into estate agency — though they should check out in advance that they are up to the moral rigours of such a profession.”
The conclusions that I have drawn were obvious to people in the business a half a century ago. (Doll & Peto, 1980) said
“If we are to recognize those important yet moderate real advances in therapy which can save thousands of lives, then we need more large randomised trials than at present, not fewer. Until we have them treatment of future patients will continue to be determined by unreliable evidence.”
The towering figures are R.A. Fisher, and his followers who developed the ideas of randomisation and maximum likelihood estimation. In the medical area, Bradford Hill, Archie Cochrane, Iain Chalmers had the important ideas worked out a long time ago.
In contrast, philosophers like Worral, Cartwright, Holmes, Barry, Loughlin and Polychronis seem to me to make no contribution to the accumulation of useful knowledge, and in some cases to hinder it. It’s true that the harm they do is limited, but that is because they talk largely to each other. Very few working scientists are even aware of their existence. Perhaps that is just as well.
References
Cartwright N (2007). Are RCTs the Gold Standard? Biosocieties (2007), 2: 11-20
Colquhoun, D (2010) University of Buckingham does the right thing. The Faculty of Integrated Medicine has been fired. https://www.dcscience.net/?p=2881
Miles A & Loughlin M (2006). Continuing the evidence-based health care debate in 2006. The progress and price of EBM. J Eval Clin Pract 12, 385-398.
Miles A, Loughlin M, & Polychronis A (2007). Medicine and evidence: knowledge and action in clinical practice. J Eval Clin Pract 13, 481-503.
Miles A, Polychronis A, & Grey JE (2006). The evidence-based health care debate – 2006. Where are we now? J Eval Clin Pract 12, 239-247.
Murray SJ, Holmes D, Perron A, & Rail G (2007).
Deconstructing the evidence-based discourse in health sciences: truth, power and fascis. Int J Evid Based Healthc 2006; : 4, 180–186.
Sokal AD (1996). Transgressing the Boundaries: Towards a Transformative Hermeneutics of Quantum Gravity. Social Text 46/47, Science Wars, 217-252.
Sokal AD (2006). Pseudoscience and Postmodernism: Antagonists or Fellow-Travelers? In Archaeological Fantasies, ed. Fagan GG, Routledge,an imprint of Taylor & Francis Books Ltd.
Sokal AD & Bricmont J (1998). Intellectual Impostures, New edition, 2003, Economist Books ed. Profile Books.
Tallis R. (1999) Sokal and Bricmont: Is this the beginning of the end of the dark ages in the humanities?
Worrall J. (2004) Why There’s No Cause to Randomize. Causality: Metaphysics and Methods.Technical Report 24/04 . 2004.
Worrall J (2010). Evidence: philosophy of science meets medicine. J Eval Clin Pract 16, 356-362.
Follow-up
Iain Chalmers has drawn my attention to a some really interesting papers in the James Lind Library
An account of early trials is given by Chalmers I, Dukan E, Podolsky S, Davey Smith G (2011). The adoption of unbiased treatment allocation schedules in clinical trials during the 19th and early 20th centuries. Fisher was not the first person to propose randomised trials, but he is the person who put it on a sound mathematical basis.
Another fascinating paper is Chalmers I (2010). Why the 1948 MRC trial of streptomycin used treatment allocation based on random numbers.
The distinguished statistician, David Cox contributed, Cox DR (2009). Randomization for concealment.
Incidentally, if anyone still thinks there are ethical objections to random allocation, they should read the account of retrolental fibroplasia outbreak in the 1950s, Silverman WA (2003). Personal reflections on lessons learned from randomized trials involving newborn infants, 1951 to 1967.
Chalmers also pointed out that Antony Eagle of Exeter College Oxford had written about Goldacre’s epistemology. He describes himself as a “formal epistemologist”. I fear that his criticisms seem to me to be carping and trivial. Once again, a philosopher has failed to make a contribution to the progress of knowledge.
This article has been reposted on The Winnower, and now has a digital object identifier DOI: 10.15200/winn.142934.47856
This post is not about quackery, nor university politics. It is about inference, How do we know what we should eat? The question interests everyone, but what do we actually know? Not as much as you might think from the number of column-inches devoted to the topic. The discussion below is a synopsis of parts of an article called “In praise of randomisation”, written as a contribution to a forthcoming book, Evidence, Inference and Enquiry.
About a year ago just about every newspaper carried a story much like this one in the Daily Telegraph,
|
Sausage a day can increase bowel cancer risk By Rebecca Smith, Medical Editor Last Updated: 1:55AM BST 31/03/2008
|
||||

What, I wondered, was the evidence behind these dire warnings. They did not come from a lifestyle guru, a diet faddist or a supplement salesman. This is nothing to do with quackery. The numbers come from the 2007 report of the World Cancer Research Fund and American Institute for Cancer Research, with the title ‘Food, Nutrition, Physical Activity, and the Prevention of Cancer: a Global Perspective‘. This is a 537 page report with over 4,400 references. Its panel was chaired by Professor Sir Michael Marmot, UCL’s professor of Epidemiology and Public Health. He is a distinguished epidemiologist, renowned for his work on the relation between poverty and health.
Nevertheless there has never been a randomised trial to test the carcinogenicity of bacon, so it seems reasonable to ask how strong is the evidence that you shouldn’t eat it? It turns out to be surprisingly flimsy.
In praise of randomisation
Everyone knows about the problem of causality in principle. Post hoc ergo propter hoc; confusion of sequence and consequence; confusion of correlation and cause. This is not a trivial problem. It is probably the main reason why ineffective treatments often appear to work. It is traded on by the vast and unscrupulous alternative medicine industry. It is, very probably, the reason why we are bombarded every day with conflicting advice on what to eat. This is a bad thing, for two reasons. First, we end up confused about what we should eat. But worse still, the conflicting nature of the advice gives science as a whole a bad reputation. Every time a white-coated scientist appears in the media to tell us that a glass of wine per day is good/bad for us (delete according to the phase of the moon) the general public just laugh.
In the case of sausages and bacon, suppose that there is a correlation between eating them and developing colorectal cancer. How do we know that it was eating the bacon that caused the cancer – that the relationship is causal? The answer is that there is no way to be sure if we have simply observed the association. It could always be that the sort of people who eat bacon are also the sort of people who get colorectal cancer. But the question of causality is absolutely crucial, because if it is not causal, then stopping eating bacon won’t reduce your risk of cancer. The recommendation to avoid all processed meat in the WCRF report (2007) is sensible only if the relationship is causal. Barker Bausell said:
[Page39] “But why should nonscientists care one iota about something as esoteric as causal inference? I believe that the answer to this question is because the making of causal inferences is part of our job description as Homo Sapiens.”
That should be the mantra of every health journalist, and every newspaper reader.
|
The essential basis for causal inference was established over 70 years ago by that giant of statistics Ronald Fisher, and that basis is randomisation. Its first popular exposition was in Fisher’s famous book, The Design of Experiments (1935). The Lady Tasting Tea has become the classical example of how to design an experiment. . |
|
Briefly, a lady claims to be able to tell whether the milk was put in the cup before or after the tea was poured. Fisher points out that to test this you need to present the lady with an equal number of cups that are ‘milk first’ or ‘tea first’ (but otherwise indistinguishable) in random order, and count how many she gets right. There is a beautiful analysis of it in Stephen Senn’s book, Dicing with Death: Chance, Risk and Health. As it happens, Google books has the whole of the relevant section Fisher’s tea test (geddit?), but buy the book anyway. Such is the fame of this example that it was used as the title of a book, The Lady Tasting Tea was published by David Salsburg (my review of it is here)
Most studies of diet and health fall into one of three types, case-control studies, cohort (or prospective) studies, or randomised controlled trials (RCTs). Case-control studies are the least satisfactory: they look at people who already have the disease and look back to see how they differ from similar people who don’t have the disease. They are retrospective. Cohort studies are better because they are prospective: a large group of people is followed for a long period and their health and diet is recorded and later their disease and death is recorded. But in both sorts of studies,each person decides for him/herself what to eat or what drugs to take. Such studies can never demonstrate causality, though if the effect is really big (like cigarette-smoking and lung cancer) they can give a very good indication. The difference in an RCT is that each person does not choose what to eat, but their diet is allocated randomly to them by someone else. This means that, on average, all other factors that might influence the response are balanced equally between the two groups. Only RCTs can demonstrate causality.
Randomisation is a rather beautiful idea. It allows one to remove, in a statistical sense, bias that might result from all the sources that you hadn’t realised were there. If you are aware of a source of bias, then measure it. The danger arises from the things you don’t know about, or can’t measure (Senn, 2004; Senn, 2003). Although it guarantees freedom from bias only in a long run statistical sense, that is the best that can be done. Everything else is worse.
Ben Goldacre has referred memorably to the newspapers’ ongoing “Sisyphean task of dividing all the inanimate objects in the world into the ones that either cause or cure cancer” (Goldacre, 2008). This has even given rise to a blog. “The Daily Mail Oncological Ontology Project“. The problem arises in assessing causality.
It wouldn’t be so bad if the problem were restricted to the media. It is much more worrying that the problem of establishing causality often seems to be underestimated by the authors of papers themselves. It is a matter of speculation why this happens. Part of the reason is, no doubt, a genuine wish to discover something that will benefit mankind. But it is hard not to think that hubris and self-promotion may also play a role. Anything whatsoever that purports to relate diet to health is guaranteed to get uncritical newspaper headlines.
At the heart of the problem lies the great difficulty in doing randomised studies of the effect of diet and health. There can be no better illustration of the vital importance of randomisation than in this field. And, notwithstanding the generally uncritical reporting of stories about diet and health, one of the best accounts of the need for randomisation was written by a journalist, Gary Taubes, and it appeared in the New York Times (Taubes, 2007).
The case of hormone replacement therapy
In the 1990s hormone replacement therapy (HRT) was recommended not only to relieve the unpleasant symptoms of the menopause, but also because cohort studies suggested that HRT would reduce heart disease and osteoporosis in older women. For these reasons, by 2001, 15 million US women (perhaps 5 million older women) were taking HRT (Taubes, 2007). These recommendations were based largely on the Harvard Nurses’ Study. This was a prospective cohort study in which 122,000 nurses were followed over time, starting in 1976 (these are the ones who responded out of the 170,000 requests sent out). In 1994, it was said (Manson, 1994) that nearly all of the more than 30 observational studies suggested a reduced risk of coronary heart disease (CHD) among women receiving oestrogen therapy. A meta-analysis gave an estimated 44% reduction of CHD. Although warnings were given about the lack of randomised studies, the results were nevertheless acted upon as though they were true. But they were wrong. When proper randomised studies were done, not only did it turn out that CHD was not reduced: it was actually increased.
The Women’s Health Initiative Study (Rossouw et al., 2002) was a randomized double blind trial on 16,608 postmenopausal women aged 50-79 years and its results contradicted the conclusions from all the earlier cohort studies. HRT increased risks of heart disease, stroke, blood clots, breast cancer (though possibly helped with osteoporosis and perhaps colorectal cancer). After an average 5.2 years of follow-up, the trial was stopped because of the apparent increase in breast cancer in the HRT group. The relative risk (HRT relative to placebo) of CHD was 1.29 (95% confidence interval 1.02 to 1.63) (286 cases altogether) and for breast cancer 1.26 (1.00 -1.59) (290 cases). Rather than there being a 44% reduction of risk, it seems that there was actually a 30% increase in risk. Notice that these are actually quite small risks, and on the margin of statistical significance. For the purposes of communicating the nature of the risk to an individual person it is usually better to specify the absolute risk rather than relative risk. The absolute number of CHD cases per 10,000 person-years is about 29 on placebo and 36 on HRT, so the increased risk of any individual is quite small. Multiplied over the whole population though, the number is no longer small.
Several plausible reasons for these contradictory results are discussed by Taubes,(2007): it seems that women who choose to take HRT are healthier than those who don’t. In fact the story has become a bit more complicated since then: the effect of HRT depends on when it is started and on how long it is taken (Vandenbroucke, 2009).
This is perhaps one of the most dramatic illustrations of the value of randomised controlled trials (RCTs). Reliance on observations of correlations suggested a 44% reduction in CHD, the randomised trial gave a 30% increase in CHD. Insistence on randomisation is not just pedantry. It is essential if you want to get the right answer.
Having dealt with the cautionary tale of HRT, we can now get back to the ‘Sisyphean task of dividing all the inanimate objects in the world into the ones that either cause or cure cancer’.
The case of processed meat
The WCRF report (2007) makes some pretty firm recommendations.
- Don’t get overweight
- Be moderately physically active, equivalent to brisk walking for at least 30 minutes every day
- Consume energy-dense foods sparingly. Avoid sugary drinks. Consume ‘fast foods’ sparingly, if at all
- Eat at least five portions/servings (at least 400 g or 14 oz) of a variety of non-starchy vegetables and of fruits every day. Eat relatively unprocessed cereals (grains) and/or pulses (legumes) with every meal. Limit refined starchy foods
- People who eat red meat to consume less than 500 g (18 oz) a week, very little if any to be processed.
- If alcoholic drinks are consumed, limit consumption to no more than two drinks a day for men and one drink a day for women.
- Avoid salt-preserved, salted, or salty foods; preserve foods without using salt. Limit consumption of processed foods with added salt to ensure an intake of less than 6 g (2.4 g sodium) a day.
- Dietary supplements are not recommended for cancer prevention.
These all sound pretty sensible but they are very prescriptive. And of course the recommendations make sense only insofar as the various dietary factors cause cancer. If the association is not causal, changing your diet won’t help. Note that dietary supplements are NOT recommended. I’ll concentrate on the evidence that lies behind “People who . . . very little if any to be processed.”
The problem of establishing causality is dicussed in the report in detail. In section 3.4 the report says
” . . . causal relationships between food and nutrition, and physical activity can be confidently inferred when epidemiological evidence, and experimental and other biological findings, are consistent, unbiased, strong, graded, coherent, repeated, and plausible.”
The case of processed meat is dealt with in chapter 4.3 (p. 148) of the report.
“Processed meats” include sausages and frankfurters, and ‘hot dogs’, to which nitrates/nitrites or other preservatives are added, are also processed meats. Minced meats sometimes, but not always, fall inside this definition if they are preserved chemically. The same point applies to ‘hamburgers’.
The evidence for harmfulness of processed meat was described as “convincing”, and this is the highest level of confidence in the report, though this conclusion has been challenged (Truswell, 2009) .
How well does the evidence obey the criteria for the relationship being causal?
Twelve prospective cohort studies showed increased risk for the highest intake group when compared to the lowest, though this was statistically significant in only three of them. One study reported non-significant decreased risk and one study reported that there was no effect on risk. These results are summarised in this forest plot (see also Lewis & Clark, 2001)
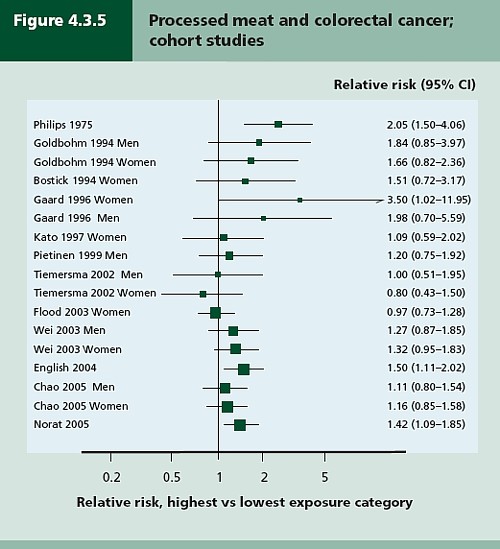
Each line represents a separate study. The size of the square represents the precision (weight) for each. The horizontal bars show the 95% confidence intervals. If it were possible to repeat the observations many times on the same population, the 95% CL would be different on each repeat experiment, but 19 out of 20 (95%) of the intervals would contain the true value (and 1 in 20 would not contain the true value). If the bar does not overlap the vertical line at relative risk = 1 (i.e. no effect) this is equivalent to saying that there is a statistically significant difference from 1 with P < 0.05. That means, very roughly, that there is a 1 in 20 chance of making a fool of yourself if you claim that the association is real, rather than being a result of chance (more detail here),
There is certainly a tendency for the relative risks to be above one, though not by much, Pooling the results sounds like a good idea. The method for doing this is called meta-analysis .
Meta-analysis was possible on five studies, shown below. The outcome is shown by the red diamond at the bottom, labelled “summary effect”, and the width of the diamond indicates the 95% confidence interval. In this case the final result for association between processed meat intake and colorectal cancer was a relative risk of 1.21 (95% CI 1.04–1.42) per 50 g/day. This is presumably where the headline value of a 20% increase in risk came from.
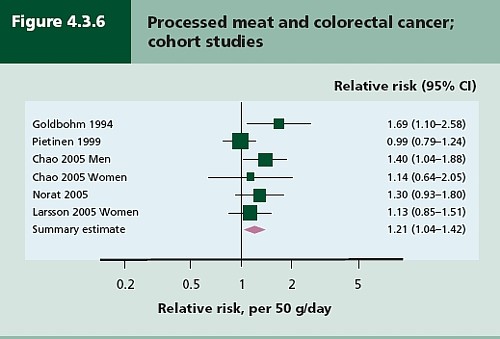
Support came from a meta-analysis of 14 cohort studies, which reported a relative risk for processed meat of 1.09 (95% CI 1.05 – 1.13) per 30 g/day (Larsson & Wolk, 2006). Since then another study has come up with similar numbers (Sinha etal. , 2009). This consistency suggests a real association, but it cannot be taken as evidence for causality. Observational studies on HRT were just as consistent, but they were wrong.
The accompanying editorial (Popkin, 2009) points out that there are rather more important reasons to limit meat consumption, like the environmental footprint of most meat production, water supply, deforestation and so on.
So the outcome from vast numbers of observations is an association that only just reaches the P = 0.05 level of statistical significance. But even if the association is real, not a result of chance sampling error, that doesn’t help in the least in establishing causality.
There are two more criteria that might help, a good relationship between dose and response, and a plausible mechanism.
Dose – response relationship
|
It is quite possible to observe a very convincing relationship between dose and response in epidemiological studies, The relationship between number of cigarettes smoked per day and the incidence of lung cancer is one example. Indeed it is almost the only example. |
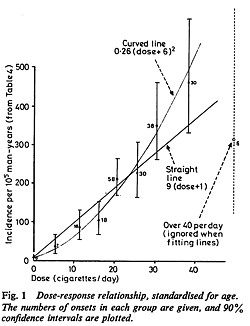 Doll & Peto, 1978 |
There have been six studies that relate consumption of processed meat to incidence of colorectal cancer. All six dose-response relationships are shown in the WCRG report. Here they are.
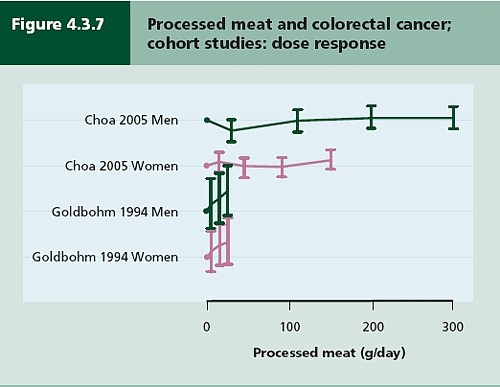
This Figure was later revised to
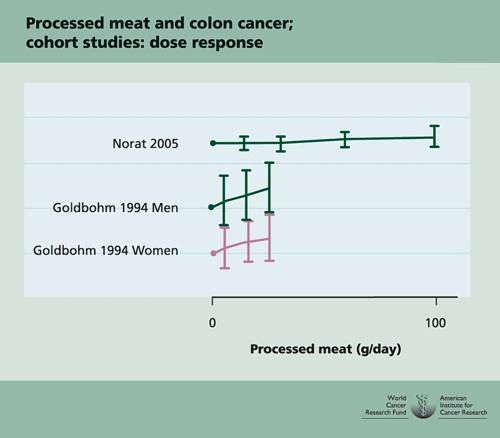
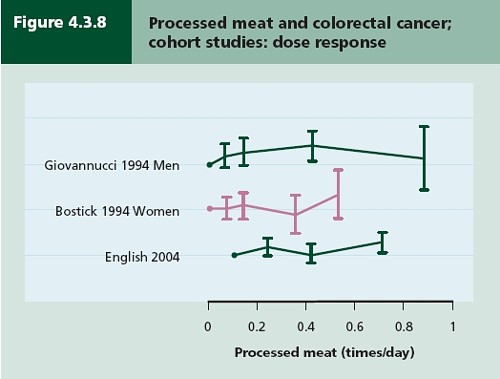
This is the point where my credulity begins to get strained. Dose – response curves are part of the stock in trade of pharmacologists. The technical description of these six curves is, roughly, ‘bloody horizontal’. The report says “A dose-response relationship was also apparent from cohort studies that measured consumption in times/day”. I simply cannot agree that any relationship whatsoever is “apparent”.
They are certainly the least convincing dose-response relationships I have ever seen. Nevertheless a meta-analysis came up with a slope for response curve that just reached the 5% level of statistical significance.
The conclusion of the report for processed meat and colorectal cancer was as follows.
“There is a substantial amount of evidence, with a dose-response relationship apparent from cohort studies. There is strong evidence for plausible mechanisms operating in humans. Processed meat is a convincing cause of colorectal cancer.”
But the dose-response curves look appalling, and it is reasonable to ask whether public policy should be based on a 1 in 20 chance of being quite wrong (1 in 20 at best –see Senn, 2008). I certainly wouldn’t want to risk my reputation on odds like that, never mind use it as a basis for public policy.
So we are left with plausibility as the remaining bit of evidence for causality. Anyone who has done much experimental work knows that it is possible to dream up a plausible explanation of any result whatsoever. Most are wrong and so plausibility is a pretty weak argument. Much play is made of the fact that cured meats contain nitrates and nitrites, but there is no real evidence that the amount they contain is harmful.
The main source of nitrates in the diet is not from meat but from vegetables (especially green leafy vegetables like lettuce and spinach) which contribute 70 – 90% of total intake. The maximum legal content in processed meat is 10 – 25 mg/100g, but lettuce contains around 100 – 400 mg/100g with a legal limit of 200 – 400 mg/100g. Dietary nitrate intake was not associated with risk for colorectal cancer in two cohort studies.(Food Standards Agency, 2004; International Agency for Research on Cancer, 2006).
To add further to the confusion, another cohort study on over 60,000 people compared vegetarians and meat-eaters. Mortality from circulatory diseases and mortality from all causes were not detectably different between vegetarians and meat eaters (Key et al., 2009a). Still more confusingly, although the incidence of all cancers combined was lower among vegetarians than among meat eaters, the exception was colorectal cancer which had a higher incidence in vegetarians than in meat eaters (Key et al., 2009b).
Mente et al. (2009) compared cohort studies and RCTs for effects of diet on risk of coronary heart disease. “Strong evidence” for protective effects was found for intake of vegetables, nuts, and “Mediterranean diet”, and harmful effects of intake of trans–fatty acids and foods with a high glycaemic index. There was also a bit less strong evidence for effects of mono-unsaturated fatty acids and for intake of fish, marine ω-3 fatty acids, folate, whole grains, dietary vitamins E and C, beta carotene, alcohol, fruit, and fibre. But RCTs showed evidence only for “Mediterranean diet”, and for none of the others.
As a final nail in the coffin of case control studies, consider pizza. According to La Vecchia & Bosetti (2006), data from a series of case control studies in northern Italy lead to: “An inverse association was found between regular pizza consumption (at least one portion of pizza per week) and the risk of cancers of the digestive tract, with relative risks of 0.66 for oral and pharyngeal cancers, 0.41 for oesophageal, 0.82 for laryngeal, 0.74 for colon and 0.93 for rectal cancers.”
What on earth is one meant to make of this? Pizza should be prescribable on the National Health Service to produce a 60% reduction in oesophageal cancer? As the authors say “pizza may simply represent a general and aspecific indicator of a favourable Mediterranean diet.” It is observations like this that seem to make a mockery of making causal inferences from non-randomised studies. They are simply uninterpretable.
Is the observed association even real?
The most noticeable thing about the effects of red meat and processed meat is not only that they are small but also that they only just reach the 5 percent level of statistical significance. It has been explained clearly why, in these circumstances, real associations are likely to be exaggerated in size (Ioannidis, 2008a; Ioannidis, 2008b; Senn, 2008). Worse still, there as some good reasons to think that many (perhaps even most) of the effects that are claimed in this sort of study are not real anyway (Ioannidis, 2005). The inflation of the strength of associations is expected to be bigger in small studies, so it is noteworthy that the large meta-analysis by Larsson & Wolk, 2006 comments “In the present meta-analysis, the magnitude of the relationship of processed meat consumption with colorectal cancer risk was weaker than in the earlier meta-analyses”.
This is all consistent with the well known tendency of randomized clinical trials to show initially a good effect of treatment but subsequent trials tend to show smaller effects. The reasons, and the cures, for this worrying problem are discussed by Chalmers (Chalmers, 2006; Chalmers & Matthews, 2006; Garattini & Chalmers, 2009)
What do randomized studies tell us?
The only form of reliable evidence for causality comes from randomised controlled trials. The difficulties in allocating people to diets over long periods of time are obvious and that is no doubt one reason why there are far fewer RCTs than there are observational studies. But when they have been done the results often contradict those from cohort studies. The RCTs of hormone replacement therapy mentioned above contradicted the cohort studies and reversed the advice given to women about HRT.
Three more illustrations of how plausible suggestions about diet can be refuted by RCTs concern nutritional supplements and weight-loss diets
Many RCTs have shown that various forms of nutritional supplement do no good and may even do harm (see Cochrane reviews). At least we now know that anti-oxidants per se do you no good. The idea that anti-oxidants might be good for you was never more than a plausible hypothesis, and like so many plausible hypotheses it has turned out to be a myth. The word anti-oxidant is now no more than a marketing term, though it remains very profitable for unscrupulous salesmen.
The randomised Women’s Health Initiative Dietary Modification Trial (Prentice et al., 2007; Prentice, 2007) showed minimal effects of dietary fat on cancer, though the conclusion has been challenged on the basis of the possible inaccuracy of reported diet (Yngve et al., 2006).
Contrary to much dogma about weight loss (Sacks et al., 2009) found no differences in weight loss over two years between four very different diets. They assigned randomly 811 overweight adults to one of four diets. The percentages of energy derived from fat, protein, and carbohydrates in the four diets were 20, 15, and 65%; 20, 25, and 55%; 40, 15, and 45%; and 40, 25, and 35%. No difference could be detected between the different diets: all that mattered for weight loss was the total number of calories. It should be added, though, that there were some reasons to think that the participants may not have stuck to their diets very well (Katan, 2009).
The impression one gets from RCTs is that the details of diet are not anything like as important as has been inferred from non-randomised observational studies.
So does processed meat give you cancer?
After all this, we can return to the original question. Do sausages or bacon give you colorectal cancer? The answer, sadly, is that nobody really knows. I do know that, on the basis of the evidence, it seems to me to be an exaggeration to assert that “The evidence is convincing that processed meat is a cause of bowel cancer”.
In the UK there were around 5 cases of colorectal cancer per 10,000 population in 2005, so a 20% increase, even if it were real, and genuinely causative. would result in 6 rather than 5 cases per 10,000 people, annually. That makes the risk sound trivial for any individual. On the other hand there were 36,766 cases of colorectal cancer in the UK in 2005. A 20% increase would mean, if the association were causal, about 7000 extra cases as a result of eating processed meat, but no extra cases if the association were not causal.
For the purposes of public health policy about diet, the question of causality is crucial. One has sympathy for the difficult decisions that they have to make, because they are forced to decide on the basis of inadequate evidence.
If it were not already obvious, the examples discussed above make it very clear that the only sound guide to causality is a properly randomised trial. The only exceptions to that are when effects are really big. The relative risk of lung cancer for a heavy cigarette smoker is 20 times that of a non-smoker and there is a very clear relationship between dose (cigarettes per day) and response (lung cancer incidence), as shown above. That is a 2000% increase in risk, very different from the 20% found for processed meat (and many other dietary effects). Nobody could doubt seriously the causality in that case.
The decision about whether to eat bacon and sausages has to be a personal one. It depends on your attitude to the precautionary principle. The observations do not, in my view, constitute strong evidence for causality, but they are certainly compatible with causality. It could be true so if you want to be on the safe side then avoid bacon. Of course life would not be much fun if your actions were based on things that just could be true.
My own inclination would be to ignore any relative risk based on observational data if it was less than about 2. The National Cancer Institute (Nelson, 2002) advises that relative risks less than 2 should be “viewed with caution”, but fails to explain what “viewing with caution” means in practice, so the advice isn’t very useful.
In fact hardly any of the relative risks reported in the WCRF report (2007) reach this level. Almost all relative risks are less than 1.3 (or greater than 0.7 for alleged protective effects). Perhaps it is best to stop worrying and get on with your life. At some point it becomes counterproductive to try to micromanage `people’s diet on the basis of dubious data. There is a price to pay for being too precautionary. It runs the risk of making people ignore information that has got a sound basis. It runs the risk of excessive medicalisation of everyday life. And it brings science itself into disrepute when people laugh at the contradictory findings of observational epidemiology.
The question of how diet and other ‘lifestyle interventions’ affect health is fascinating to everyone. There is compelling reason to think that it matters. For example one study demonstrated that breast cancer incidence increased almost threefold in first-generation Japanese women who migrated to Hawaii, and up to fivefold in the second generation (Kolonel, 1980). Since then enormous effort has been put into finding out why. The first great success was cigarette smoking but that is almost the only major success. Very few similar magic bullets have come to light after decades of searching (asbestos and mesothelioma, or UV radiation and skin cancer count as successes).
The WCRF report (2007) has 537 pages and over 4400 references and we still don’t know.
Sometimes I think we should say “I don’t know” rather more often.
More material
-
Listen to Ben Goldacre’s Radio 4 programmes. The Rise of the Lifetsyle Nutritionists. Part 1 and Part 2 (mp3 files), and at badscience.net.
-
Risk The Science and Politics of Fear, Dan Gardner. Virgin
Books, 2008 -
Some bookmarks about diet and supplements
Follow up
Dan Gardner, the author of Risk, seems to like the last line at least, according to his blog.
Report of the update, 2010
The 2010 report has been updated in WCRF/AICR Systematic Literature Review Continuous Update Project Report [big pdf file]. This includes studies up to May/June 2010.
The result of addition of the new data was to reduce slightly the apparent risk from eating processed meat from 1.21 (95% CI = 1.04-1.42) in the original study to 1.18 (95% CI = 1.10-1.28) in the update. The change is too small to mean much, though it is in direction expected for false correlations. More importantly, the new data confirm that the dose-response curves are pathetic. The evidence for causality is weakened somewhat by addition of the new data.
Dose-response graph of processed meat and colorectal cancer