
Download Lectures on Biostatistics (1971). Corrected and searchable version of Google books edition
Download review of Lectures on Biostatistics (THES, 1973).
Open access is in the news again.
Index on Censorship held a debate on open data on December 6th.
|
The video of of the meeting is now on YouTube. A couple of dramatic moments in the video: At 48 min O’Neill & Monbiot face off about "competent persons" (and at 58 min Walport makes fun of my contention that it’s better to have more small grants rather than few big ones, on the grounds that it’s impossible to select the stars). |

|
The meeting has been written up on the Bishop Hill Blog, with some very fine cartoon minutes.
 (I love the Josh cartoons -pity he seems to be a climate denier, spoken of approvingly by the unspeakable James Delingpole.)
(I love the Josh cartoons -pity he seems to be a climate denier, spoken of approvingly by the unspeakable James Delingpole.)
It was gratifying that my remarks seemed to be better received by the scientists in the audience than they were by some other panel members. The Bishop Hill blog comments "As David Colquhoun, the only real scientist there and brilliant throughout, said “Give them everything!” " Here’s a subsection of the brilliant cartoon minutes

The bit about "I just lied -but he kept his job" referred to the notorious case of Richard Eastell and the University of Sheffield.
We all agreed that papers should be open for anyone to read, free. Monbiot and I both thought that raw data should be available on request, though O’Neill and Walport had a few reservations about that.
A great deal of time and money would be saved if data were provided on request. It shouldn’t need a Freedom of Information Act (FOIA) request, and the time and energy spent on refusing FOIA requests is silly. It simply gives the impression that there is something to hide (Climate scientists must be ruthlessly honest about data). The University of Central Lancashire spent £80,000 of taxpayers’ money trying (unsuccessfully) to appeal against the judgment of the Information Commissioner that they must release course material to me. It’s hard to think of a worse way to spend money.
A few days ago, the Department for Business, Innovation and Skills (BIS) published a report which says (para 6.6)
“The Government . . . is committed to ensuring that publicly-funded research should be accessible
free of charge.”
That’s good, but how it can be achieved is less obvious. Scientific publishing is, at the moment, an unholy mess. It’s a playground for profiteers. It runs on the unpaid labour of academics, who work to generate large profits for publishers. That’s often been said before, recently by both George Monbiot (Academic publishers make Murdoch look like a socialist) and by me (Publish-or-perish: Peer review and the corruption of science). Here are a few details.
Extortionate cost of publishing
Mark Walport has told me that
The Wellcome Trust is currently spending around £3m pa on OA publishing costs and, looking at the Wellcome papers that find their way to UKPMC, we see that around 50% of this content is routed via the “hybrid option”; 40% via the “pure” OA journals (e.g. PLoS, BMC etc), and the remaining 10% through researchers self-archiving their author manuscripts.
I’ve found some interesting numbers, with help from librarians, and through access to The Journal Usage Statistics Portal (JUSP).
Elsevier
UCL pays Elsevier the astonishing sum of €1.25 million, for access to its journals. And that’s just one university. That price doesn’t include any print editions at all, just web access and there is no open access. You have to have a UCL password to see the results. Elsevier has, of course, been criticised before, and not just for its prices.
Elsevier publish around 2700 scientific journals. UCL has bought a package of around 2100 journals. There is no possibility to pick the journals that you want. Some of the journals are used heavily ("use" means access of full text on the web). In 2010, the most heavily used journal was The Lancet, followed by four Cell Press journals
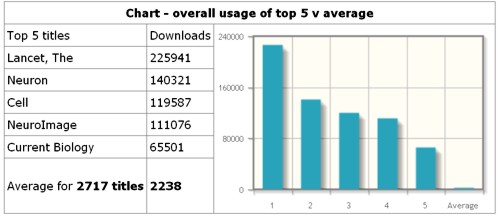
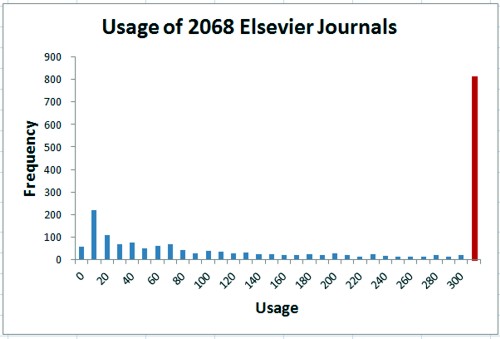
But notice the last bin. Most of the journals are hardly used at all. Among all Elsevier journals, 251 were not accessed even once in 2010. Among the 2068 journals bought by UCL, 56 were never accessed in 2010 and the most frequent number of accesses per year is between 1 and 10 (the second bin in the histogram, below). 60 percent of journals have 300 or fewer usages in 2010, Above 300, the histogram tails on up to 51878 accesses for The Lancet. The remaining 40 percent of journals are represented by the last bin (in red). The distribution is exceedingly skewed. The median is 187, i.e. half of the journals had fewer than 187 usages in 2010), but the mean number of usages (which is misleading for such a skewed distribution, was 662 usages).
Nature Publishing Group
UCL bought 65 journals from NPG in 2010. They get more use than Elsevier, though surprisingly three of them were never accessed in 2010, and 17 had fewer than 1000 accesses in that year. The median usage was 2412, better than most. The leader, needless to say, was Nature itself, with 153,321.
Oxford University Press
The situation is even more extreme for 248 OUP journals, perhaps because many of the journals are arts or law rather than science.
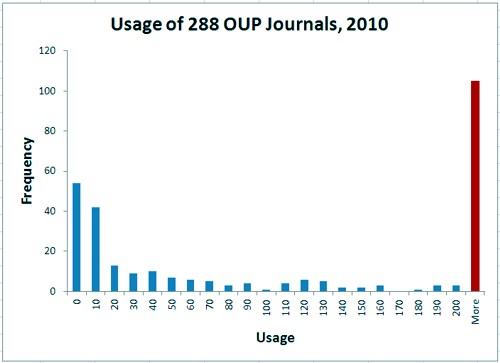
The most frequent (modal) usage of was zero (54 journals), followed by 1 to 10 accesses (42 journals) 64 percent of journals had fewer than 200 usages, and the 36 percent with over 200 are pooled in the last (red) bin. The histogram extends right up to 16060 accesses for Brain. The median number of usages in 2010 was 66.
So far I haven’t been able to discover the costs of the contracts with OUP or Nature Publishing group. It seems that the university has agreed to confidentiality clauses. This itself is a shocking lack of transparency. If I can find the numbers I shall -watch this space.
Almost all of these journals are not open access. The academics do the experiments, most often paid for by the taxpayer. They write the paper (and now it has to be in a form that is almost ready for publication without further work), they send it to the journal, where it is sent for peer review, which is also unpaid. The journal sells the product back to the universities for a high price, where the results of the work are hidden from the people who paid for it.
It’s even worse than that, because often the people who did the work and wrote the paper, have to pay "page charges". These vary, but can be quite high. If you send a paper to the Journal of Neuroscience, it will probably cost you about $1000. Other journals, like the excellent Journal of Physiology, don’t charge you to submit a paper (unless you want a colour figure in the print edition, £200), but the paper is hidden from the public for 12 months unless you pay $3000.
The major medical charity, the Wellcome Trust, requires that the work it funds should be available to the public within 6 months of publication. That’s nothing like good enough to allow the public to judge the claims of a paper which hits the newspapers the day that it’s published. Nevertheless it can cost the authors a lot. Elsevier journals charge $3000 except for their most-used journals. The Lancet charges £400 per page and Cell Press journals charge $5000 for this unsatisfactory form of open access.
Open access journals
The outcry about hidden results has resulted in a new generation of truly open access journals that are open to everyone from day one. But if you want to publish in them you have to pay quite a lot.
Furthermore, although all these journals are free to read, most of them do not allow free use of the material they publish. Most are operating under all-rights-reserved copyrights. In 2009 under 10 percent of open access journals had true Creative Commons licence.
Nature Publishing Group has a true open access journal, Nature Communications, but it costs the author $5000 to publish there. The Public Library of Science journals are truly open access but the author is charged $2900 for PLoS Medicine though PLoS One costs the author only $1350
A 2011 report considered the transition to open access publishing but it doesn’t even consider radical solutions, and makes unreasonably low estimates of the costs of open access publishing.
Scam journals have flourished under the open access flag
Open access publishing has, so far, almost always involved paying a hefty fee. That has brought the rats out of the woodwork and one gets bombarded daily with offers to publish in yet another open access journal. Many of these are simply scams. You pay, we put it on the web and we won’t fuss about quality. Luckily there is now a guide to these crooks: Jeffrey Beall’s List of Predatory, Open-Access Publishers.
One that I hear from regularly is Bentham Open Journals
(a name that is particularly inappropriate for anyone at UCL). Jeffery Beall comments
"Among the first, large-scale gold OA publishers, Bentham Open continues to expand its fleet of journals, now numbering over 230. Bentham essentially operates as a scholarly vanity press."
They undercut real journals. A research article in The Open Neuroscience Journal will cost you a mere $800. Although these journals claim to be peer-reviewed, their standards are suspect. In 2009, a nonsensical computer-generated spoof paper was accepted by a Bentham Journal (for $800),
What can be done about publication, and what can be done about grants?
Both grants and publications are peer-reviewed, but the problems need to be discussed separately.
Peer review of papers by journals
One option is clearly to follow the example of the best open access journals, such as PLoS. The cost of $3000 to 5000 per paper would have to be paid by the research funder, often the taxpayer. It would be money subtracted from the research budget, but it would retain the present peer review system and should cost no more if the money that were saved on extortionate journal subscriptions were transferred to research budgets to pay the bills, though there is little chance of this happening.
The cost of publication would, in any case, be minimised if fewer papers were published, which is highly desirable anyway.
But there are real problems with the present peer review system. It works quite well for journals that are high in the hierarchy. I have few grumbles myself about the quality of reviews, and sometimes I’ve benefitted a lot from good suggestions made by reviewers. But for the user, the process is much less satisfactory because peer review has next to no effect on what gets published in journals. All it influences is which journal the paper appears in. The only effect of the vast amount of unpaid time and effort put into reviewing is to maintain a hierarchy of journals, It has next to no effect on what appears in Pubmed.
For authors, peer review can work quite well, but
from the point of view of the consumer, peer review is useless.
It is a myth that peer review ensures the quality of what appears in the literature.
A more radical approach
I made some more radical suggestions in Publish-or-perish: Peer review and the corruption of science.
It seems to me that there would be many advantages if people simply published their own work on the web, and then opened the comments. For a start, it would cost next to nothing. The huge amount of money that goes to publishers could be put to better uses.
Another advantage would be that negative results could be published. And proper full descriptions of methods could be provided because there would be no restrictions on length.
Under that system, I would certainly send a draft paper to a few people I respected for comments before publishing it. Informal consortia might form for that purpose.
The publication bias that results from non-publication of negative results is a serious problem, mainly, but not exclusively, for clinical trials. It is mandatory to register a clinical trial before it starts, but many of the results never appear. (see, for example, Deborah Cohen’s report for Index on Censorship). Although trials now have to be registered before they start, there is no check on whether or not the results are published. A large number of registered trials do not result in any publication, and this publication bias can costs thousands of lives. It is really important to ensure that all results get published,
The ArXiv model
There are many problems that would have to be solved before we could move to self-publication on the web. Some have already been solved by physicists and mathematicians. Their archive, ArXiv.org provides an example of where we should be heading. Papers are published on the web at no cost to either user or reader, and comments can be left. It is an excellent example of post-publication peer review. Flame wars are minimised by requiring users to register, and to show they are bona fide scientists before they can upload papers or comments. You may need endorsement if you haven’t submitted before.
Peer review of grants
The problems for grants are quite different from those for papers. There is no possibility of doing away with peer review for the award of grants, however imperfect the process may be. In fact candidates for the new Wellcome Trust investigator awards were alarmed to find that the short listing of candidates for their new Investigator Awards was done without peer review.
The Wellcome Trust has been enormously important for the support of medical and biological support, and never more than now, when the MRC has become rather chaotic (let’s hope the new CEO can sort it out). There was, therefore, real consternation when Wellcome announced a while ago its intention to stop giving project and programme grants altogether. Instead it would give a few Wellcome Trust Investigator Awards to prominent people. That sounds like the Howard Hughes approach, and runs a big risk of “to them that hath shall be given”.
The awards have just been announced, and there is a good account by Colin Macilwain in Science [pdf]. UCL did reasonable well with four awards, but four is not many for a place the size of UCL. Colin Macilwain hits the nail on the head.
"While this is great news for the 27 new Wellcome Investigators who will share £57 million, hundreds of university-based researchers stand to lose Wellcome funds as the trust phases out some existing programs to pay for the new category of investigators".
There were 750 applications, but on the basis of CV alone, they were pared down to a long-list if 173. The panels then cut this down to a short-list of 55. Up to this point no external referees were used, quite unlike the normal process for award of grants. This seems to me to have been an enormous mistake. No panel, however distinguished, can have the knowledge to distinguish the good from the bad in areas outside their own work, It is only human nature to favour the sort of work you do yourself. The 55 shortlisted people were interviewed, but again by a panel with an even narrower range of expertise, Macilwain again:
"Applications for MRC grants have gone up “markedly” since the Wellcome ones closed, he says: “We still see that as unresolved.” Leszek Borysiewicz, vice-chancellor of the University of Cambridge, which won four awards, believes the impact will be positive: “Universities will adapt to this way of funding research."
It certainly isn’t obvious to most people how Cambridge or UCL will "adapt" to funding of only four people.
The Cancer Research Campaign UK has recently made the same mistake.
One problem is that any scheme of this sort will inevitably favour big groups, most of whom are well-funded already. Since there is some reason to believe that small groups are more productive (see also University Alliance report), it isn’t obvious that this is a good way to go. I was lucky enough to get 45 minutes with the director of the Wellcome Trust, Mark Walport, to put these views. He didn’t agree with all I said, but he did listen.
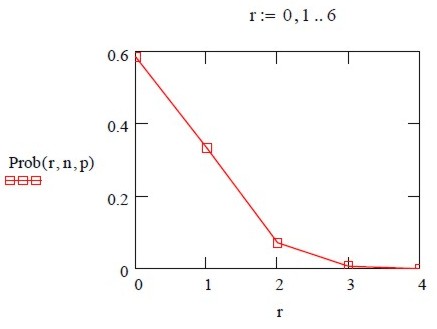
One of the things that I put to him was a small statistical calculation to illustrate the great danger of a plan that funds very few people. The funding rate was 3.6% of the original applications, and 15.6% of the long-listed applications. Let’s suppose, as a rough approximation, that the 173 long-listed applications were all of roughly equal merit. No doubt that won’t be exactly true, but I suspect it might be more nearly true than the expert panels will admit. A quick calculation in Mathcad gives this, if we assume a 1 in 8 chance of success for each application.
Distribution of the number of successful applications
Suppose $ n $ grant applications are submitted. For example, the same grant submitted $ n $ times to selection boards of equal quality, OR $ n $ different grants of equal merit are submitted to the same board.
Define $ p $ = probability of success at each application
Under these assumptions, it is a simple binomial distribution problem.
According to the binomial distribution, the probability of getting $ r $ successful applications in $ n $ attempts is
\[ P(r)=\frac{n!}{r!\left(n-r\right)! }\; {p}^{r} \left(1-p \right)^{n-r} \]
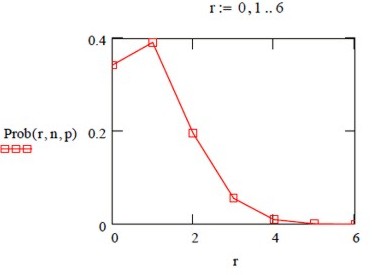
For a success rate of 1 in 8, $ p = 0.125 $, so if you make $ n = 8 $ applications, the probability that $ r $ of them will succeed is shown in the graph.
Despite equal merit, almost as many people end up with no grant at all as almost as many people end up with no grant at all as get one grant. And 26% of people will get two or more grants.
Of course it would take an entire year to write 8 applications. If we take a more realistic case of making four applications we have $ n = 4 $ (and $ p = 0.125 $, as before). In this case the graph comes out as below. You have a nearly 60% chance of getting nothing at all, and only a 1 in 3 chance of getting one grant.
These results arise regardless of merit, purely as consequence of random chance. They are disastrous, and especially disastrous for the smaller, better-value, groups for which a gap in funding can mean loss of vital expertise. It also has the consequence that scientists have to spend most of their time not doing science, but writing grant applications. The mean number of applications before a success is 8, and a third of people will have to write 9 or more applications before they get funding. This makes very little sense.
Grant-awarding panels are faced with the near-impossible task of ranking many similar grants. The peer review system is breaking down, just as it has already broken down for journal publications.
I think these considerations demolish the argument for funding a small number of ‘stars’. The public might expect that the person making the application would take an active part in the research. Too often, now, they spend most of their time writing grant applications. What we need is more responsive-mode smallish programme grants and a maximum on the size of groups.
Conclusions
We should be thinking about the following changes,
- Limit the number of papers that an individual can publish. This would increase quality, it would reduce the impossible load on peer reviewers and it would reduce costs.
- Limit the size of labs so that more small groups are encouraged. This would increase both quality and value for money.
- More (and so smaller) grants are essential for innovation and productivity.
- Move towards self-publishing on the web so the cost of publishing becomes very low rather than the present extortionate costs. It would also mean that negative results could be published easily and that methods could be described in proper detail.
The entire debate is now on YouTube.
Follow-up
24 January 2012. The eminent mathematician, Tim Gowers, has a rather hard-hitting blog on open access and scientific publishing, Elsevier – my part in its downfall. I’m right with him. Although his post lacks the detailed numbers of mine, it shows that mathematicians has exactly the same problems of the rest of us.
11 April 2012. Thanks to Twitter, I came across a remarkably prescient article, in the Guardian, in 2001.
Science world in revolt at power of the journal owners, by James Meek. Elsevier have been getting away with murder for quite a while.
19 April 2012.
|
I got invited to give after-dinner talk on open access at Cumberland Lodge. It was for the retreat of out GEE Department (that is the catchy brand name we’ve had since 2007: I’m in the equally memorable NPP). I think it stands for Genetics, Evolution and Environment. The talk seemed to stiir up a lot of interest: the discussions ran on to the next day. |

|
It was clear that younger people are still as infatuated with Nature and Science as ever. And that, of course is the fault of their elders.
The only way that I can see, is to abandon impact factor as a way of judging people. It should have gone years ago,and good people have never used it. They read the papers. Access to research will never be free until we think oi a way to break the hegemony of Nature, Science and a handful of others. Stephen Curry has made some suggestions
Probably it will take action from above. The Wellcome Trust has made a good start. And so has Harvard. We should follow their lead (see also, Stephen Curry’s take on Harvard)
And don’t forget to sign up for the Elsevier boycott. Over 10,000 academics have already signed. Tim Gowers’ initiative took off remarkably.
24 July 2012. I’m reminded by Nature writer, Richard van Noorden (@Richvn) that Nature itself has written at least twice about the iniquity of judging people by impact factors. In 2005 Not-so-deep impact said
"Only 50 out of the roughly 1,800 citable items published in those two years received more than 100 citations in 2004. The great majority of our papers received fewer than 20 citations."
"None of this would really matter very much, were it not for the unhealthy reliance on impact factors by administrators and researchers’ employers worldwide to assess the scientific quality of nations and institutions, and often even to judge individuals."
And, more recently, in Assessing assessment” (2010).
27 April 2014
The brilliant mathematician,Tim Gowers, started a real revolt against old-fashioned publishers who are desperately trying to maintain extortionate profits in a world that has changed entirely. In his 2012 post, Elsevier: my part in its downfall, he declared that he would no longer publish in, or act as referee for, any journal published by Elsevier. Please follow his lead and sign an undertaking to that effect: 14,614 people have already signed.
Gowers has now gone further. He’s made substantial progress in penetrating the wall of secrecy with which predatory publishers (of which Elsevier is not the only example) seek to prevent anyone knowing about the profitable racket they are operating. Even the confidentiality agreements, which they force universities to sign, are themselves confidential.
In a new post, Tim Gowers has provided more shocking facts about the prices paid by universities. Please look at Elsevier journals — some facts. The jaw-dropping 2011 sum of €1.25 million paid by UCL alone, is now already well out-of-date. It’s now £1,381,380. He gives figures for many other Russell Group universities too. He also publishes some of the obstructive letters that he got in the process of trying to get hold of the numbers. It’s a wonderful aspect of the web that it’s easy to shame those who deserve to be shamed.
I very much hope the matter is taken to the Information Commissioner, and that a precedent is set that it’s totally unacceptable to keep secret what a university pays for services.

Excellent post. I am amazed and worried that there are so few of us who are appalled by the charges for publishing and the lack of rights for anyone – especially authors and readers. I have been challenging the very high fees for “hybrid OA” and the fact that almost no publishers give full Open Acces as defined by the Budapest declaration.
see http://blogs.ch.cam.ac.uk/pmr for recent posts
Excellent analysis of a very important issue for the future of scientific discovery
I can’t access the “good account by Colin Macilwain in Science” on the Wellcome Investigator Awards without paying a fee to the journal. Ironic or what?
The average Investigator Award works out at just over £2 million per successful applicant, which — over 7 years — is not a lot more than was given in the old-style programme grants. So perhaps the new funding will amount to a switch to programme-only types of award (no project grants).
The one downside of self-publishing of research on authors’ own websites is the omission of a formal archiving process. Self-publication allows authors to ‘revise’ portions of their work in the light of comments or other, better findings. If archiving can be satisfactorily achieved then the sooner we do away with the huge and unnecessary charges faced for publication, the better.
@FrankO
Yes irony indeed. Try again (or here).
You are right that proper archiving is essential. That’s done very well (at no cost to user) by ArXiv, which is one of the possibilities that I suggested.
Another possibility is that it might be done by the British Library (they archive this blog, so why not my papers?).
This an interesting post and good food for thought. I worry about the ‘usable’ data from downloads as data and data from one Uni but that being said, I see your point about journal prices… But i am not sure that is a good argument for open access… Would there just be more data no one would look at?
I worry about getting rid of peer review altogether, it can be valuable in clarifying science, when referees tell you about literature you may have missed, by pure accident. Good peer review which does happen is very valuable to me as a scientist.
Limiting what you can publish per year I fear is much too strict, what if you want to get it put there fast to get feed back? .
Collating scientific info is one service journals supply, how would you find all of the info if everyone just published freely on the web, it people know you and your research, this is fine, but what about if you are new?
I just worry about throwing the baby out with the bath water, as maybe more subtle solutions are better?
@Sylvia
Thanks very much for the feedback. It’s a good example of post-publication peer review.
I hope I made it clear that there are a lot of details to be worked out, as with any change. I’ll comment on your points in turn,
The usage data is pretty well hidden, and I was lucky to be able to get the values for UCL, never mind anywhere else. I don’t know why it’s clouded in secrecy. It shouldn’t be. I found it interesting that we have to pay a very large amount for bundles of journals, some of which are never used at all.
I didn’t suggest that we should do without peer review altogether. In fact I said explicitly that peer review is often useful for authors. This is true for top end journals. Incidentally it’s also true for bottom end journals, where authors can be sure that poor papers will get through. It is the consumers who are let down by peer review, not the authors. I don’t know whether post-publication peer review can be made to work well, but the ArXiv system seems to work pretty well.
Everyone seems to agree that far too many papers are published, and that that’s largely a result of pressure from senior university managers, the research councils, and the REF. It’s the insane publish or perish mentality and it does huge harm to science and public trust. Of course any limit would have to refer to an average rate over at least five years. Anyone who has run a lab knows that papers don’t come at a uniform rate. Recently we spent four years trying to solve various technical problems in single ion channel recordings, and wondering how they should be interpreted. This resulted in quite a gap in publications, but once the problems had been worked out, old data became interpretable, and several papers came along at once. One way to implement a limit would be to allow only three or four best papers to be submitted with a grant application. We already do that for jobs and the REF does it too. It certainly helps to minimise salami-slicing of publications. But as long as citation counts are used by promotion committees and grant-awarding committees, the game-playing will remain with us. I think that there is a slow change taking place. It’s now common for people who publish 10 or 20 papers a year to be viewed with suspicion.
You ask “how would you find all of the info if everyone just published freely on the web?” Does anyone still go to the library to browse through their favourite journals? Most people use web searches now, and they don’t favour people are already well-established. Of course it would always be possible to form non-commercial consortia of people with similar interests, so papers were published on a common site (a bit like science blogs organisation). That would be almost like a journal but with none of the costs. To a larger extent ArXiv already does this for physics and astronomy, and it’s free.
David
You medics are so primitive! We computer scientists have been doing open access since forever. We put everything online, on our websites or preprint servers; we compete to get papers into the top conferences, which we use as hiring fairs for postdocs; and we pretty well forget about journals. Why pay to publish in an open-access journal when no-one reads journals any more anyway? Don’t worry; you medics will catch up eventually (in maybe 20 years).
On a more serious note, you medics are screwing up big time over open data. The issue looks like being the Coalition Government’s first information policy train wreck. People like Mark Walport and Tim Kelsey have persuaded David Cameron to order all our medical records to be made available to researchers (in both academia and industry), under cover of a mystical process called “de-identification” that’s supposed to protect our privacy.
That’s bogus science. Computer scientists discovered 30 years ago that de-identification doesn’t work, except in restricted cases not usually of great interest to medical researchers. The reason is that if I know even a few things about you, I can use this to re-identify your records. Most NHS “de-identified” records still have the patient’s postcode and date of birth. See for example
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1450006
Click to access SEv2-c09.pdf
Onora O’Neill is at least starting to grok this and says “we need an answer”; and the government has told ESRC to do some research. The problem is, the science was settled by Dorothy Denning and others a generation ago. Onora wants de-identification to be assessed by “technically competent” people; so the government wants to decide who’s to be treated as technically competent. They refuse to have the privacy mechanisms of the census scrutinised by people like me in case we denounce de-identification as digital homeopathy. You co-panellist Mark Walport refuses to believe that de-identification is bogus, despite having had it explained to him on several occasions by myself and others; it’s hard to teach someone something if his job depends on not understanding it.
First policy, then evidence; and if you don’t like what the science says, hire some social scientists to go invent some more. Redefine science if you have to. Nice one, Dave.
Ross Anderson
http://www.ross-anderson.com
(Came here via Bishop Hill…)
A couple of lifetimes ago, I published research papers in engineering journals. I’d be interested to see what is currently being done in my former areas. But not at $30 a pop, when it’s me who would be paying, out of my pension.
I don’t recall ever signing over the copyright of my papers to the journals that published them – in fact I am sure that I did not. Dunno who gets the $30 when someone pays to look at one of my papers – not me. (From the occasional citations of my work, someone does look at it now and then).
@RossAnderson
Well, I’m not a medic, I’m a single molecule biophysicist/pharmacologist. But, as I say, I like the ArXiv system, and your system sounds a bit similar. It’s true that that sort of approach has been slow to catch on in all of the biological sciences.
You don’t address my main concerns, about peer review, about grant funding and the excessive number of papers.
The points you make about anonymous records are interesting, though not the point of this post. You don’t need to be a computer scientist to see that records which contain a postcode are not anonymous. But postcodes can be removed easily. Is it really so hard to achieve a satisfactory degree of anonymity?
I don’t want to get stuck in the climate change rathole per se, but I do think that climate change really is the poster child for why the current system of publishing / peer-review/research funding is broken.
It is of course far from alone, there are plenty of other (mostly social) science areas which have the same problems – Stapel the Dutch psychologist is another good example – but climate change pretty much hits every single issue at stake.
And to be honest that’s one really good reason why I’m distinctly sceptical of a lot of the global warming claims – they cannot be independently confirmed. Moreover, despite the critical importance of the results, the researchers seem to have a truly terrible attitude towards code quality. Given that almost all climate science revolves around extracting a weak signal from an extremely noisy background, the chances of a result showing up because of a coding error, let alone an unintentional misuse of a statistical function, is high. Despite this climate researchers generally fail to adhere to any of the standards developed over the decades by computer programmers and statisticians to allow later review of work to catch these problems.
The only people who publish code that others can easily replicate are the sceptical bloggers and even then it isn’t always perfect, I’ve found that even they sometimes forget to archive/document some requirements like system libraries. They do, fortunately, always respond quickly and openly with the missing information once a problem has been found.
Peer-review is another area where climate change (and the emails leaked in “climategate”) shows the limitations of the current system. Fundamentally the current anonymous peer-review mechanism seems to warp all respectable literature towards the mainstream view. It does this by making it harder to publish contrary research and by then invoking a logical circular argument: “Peer reviewed literature only supports viewpoint A, therefore viewpoint A is correct, therefore dissents from viewpoint A will not be recognized as having value, therefore peer-review will only support viewpoint A”.
One of the other things that the current system makes hard (and not just in climate change – this certainly applies all over science) is independent replication. Grant-giving bodies tend to want to fund new things so if sicentist (group) A says that, say, the moon is green then there is no easy way for scientist (group) B to get funding and publish an alternative approach that also proves that the moon is green (or disproves it). The closest you get is a research grant to also prove that Mars is green, which in the process, also checks that the moon is still green. This is a problem because if (see above) there are errors in the initial result and it turns out the moon is not green but the initial researcher thought it was because he had a green filter on his telescope, it will take a very long time for the true state to become apparent because no one will go back and check until some years of multiple researchers reporting results that fail to completely correspond with the initial reseach.
I think the largest problem is the lack of clarity regarding intellectual property rights. Many publicly funded scientists understand that their results must be published, but they often view the underlying data and source code as their own property. Setting aside all of the accusations lodged at Phil Jones, I think the reason he went to such a great extent to frustrate FOIA requests was that he viewed his data as his life’s work and wanted to protect his ability to monetize it in the future.
But, particularly with Climate Science, I think the data and methods must be publicly available. You can’t stand up in a crowded world and announce that the world is going to end, and then expect to be able to protect your ability to profit from it by keeping you data and methods secret.
@FrancisT
I almost didn’t post your comments because I adamantly refuse to let my perfectly serious proposals be dragged into a rant for climate deniers. The piece that I wrote for the Guardian about access to climate change data got more comments than anything else I’ve written, but the comments were almost all just rants. Both sides seemed to think I was on the other side (so perhaps I had it about right).
I’ll respond as best I can to yours, but no more climate change posts please.
It really will not do to stigmatise the whole of science because of people like Stapel, There are something like 1.3 million papers published per year (too many but that’s another story). It would be a miracle if there were not a few examples of fraud among that number.
I don’t know it it’s true that climate scientists are particularly bad at coding. It’s generally a bit of a struggle to use somebody else’s analysis programs. They are usually designed for number crunching, not for elegance. Some of ours are still DOS programs. They work fine, but not many people now remember that file names can’t be more that 8 + 3 characters in DOS.
I’m not a climate scientist myself and I’ve never tried to analyse myself any of their raw data. I agree that it should be possible to do so. But I think it’s quite wrong to say that it can’t be verified. Most of the data is now out there, and it shouldn’t be hard to check if a program contains outright errors. There are many different approaches and they all seem to lead to the conclusion that global warming is happening.
Neither do I believe that the case of climate shows that there is anything wrong with the peer review system. The way to make a name for yourself in science is to show that a widely-accepted idea is wrong. I suppose that if there is a lot of evidence for the widely-accepted view, you may need to produce particularly strong evidence if you wish to come to a different conclusion. That’s perfectly reasonable. If you produce strong evidence you’ll be believed. If you stand on the sidelines carping you may not be believed and that’s quite right too.
I think you are wrong too about independent replication. That’s an essential part of every branch of science. It’s true that it might be hard to get a grant if you say you want to repeat exactly something that’s already been done, but the replication arises usually as part of a project to extend existing knowledge. It’s happened to me occasionally that it’s proved impossible to replicate the reports on which a project was based. When that happens, you publish it. It’s part of the self-correcting nature of science.
I’m afraid that your comment is suffused with the sort of conspiratorial tone that makes all climate arguments so unpleasant. I simply don’t believe that there is any conspiracy to deceive the world about climate. What would anyone gain from that? As i said already, the way to make your mark is not to agree with everyone else, but to show that the consensus is wrong. Every scientist has an enormous incentive not to be part of a conspiracy. If you produce hard data, and write it up in a good journal, you’ll be believed.
OK no more climate comments please. Stick to the main points.
The academic journal swindle is one that has exercised me for some time, so I am very pleased to see your comments, with which I heartily agree. Good on you! Please keep it up.
My own interest is patristics. It’s an obscure field, I admit. Indeed I probably know personally all the people in the world who work in certain areas of it. But, since I’m merely an interested member of the public, I have no access to any of the literature published, except by underhand means. Who benefits from that? Who benefits from excluding the public from seeing the output of research, when we, the public, pay for the whole show?
Only the academic publishers.
Pre-internet, these people performed a useful service, and there really was no way that people like me *could* get access, other than by travelling to a research library
But now? The only barrier is a vested interest. I loved your statistics: well done! And yes, if you can find out what OUP are charging, then we want to know. And I wonder whether this is just science journals, or whether humanities journals are cheaper?
I’ve done a little publishing myself (“Eusebius of Caesarea: Gospel problems and solutions”, texts and translations), so I have a very exact idea of what it costs to do the various stages. It’s very cheap, in corporate terms (even cheaper when you consider what authors get paid normally). I wish I could expect a million euros back for my efforts!
Your comments on the way forward were interesting indeed. I don’t have a good suggestion on this, but this is probably the main barrier — that no, suitably high prestige way forward exists. It probably requires government intervention, of some sort, or a commission of inquiry, to get some momentum going. (Much as I hate the idea of state involvement).
Well done, anyway.
Hi David,
Regarding the number of papers published: In reducing the number, I’m assuming there must be superfluous papers produced in the grant process, or perhaps you are referring to the ‘breaking up’ of reporting into smaller papers for the sake of creating a more impressive ‘profile’ of publishing? I’m thinking here of the risk of further gatekeeping. Can the volume be reduced without risking accessibility (on the part of both researcher and reader)?
Regarding the status of publications and web searching, as a student, I already understand that some journals are more reputable than others, and while everything but the kitchen sink shows up in searches, we are encouraged to exercise some judgement regarding quality. In theory, this should mean that I can have more confidence in a reputable journal than an obscure internet vanity publisher, and I was about to suggest that this somewhat invalidated the points about reputation. But too often I’ve seen – even as a layperson! – research in reputable journals where huge confounding factors were overlooked, or conclusions almost in contradition of actual results. So perhaps journal status is indeed a defunct issue.
I’m concerned about the risk of self-perpetuating interest groups, with circular mutual review creating a veneer of academic review, so a review process with transparency remains valuable.
It costs, comparatively, peanuts, to host a website. Time, effort and expertise of individuals does deserve compensation, but many hands… how hard could it be to develop an open source, cloud based, peer reviewed journal, as a multi-institiution and public project. A Journapedia that students wouldn’t be failed for referencing.
@Helen South
Thanks for your comment. It’s great to see a student with such a clear view of the problems.
Yes, I was referring “to the ‘breaking up’ of reporting into smaller papers for the sake of creating a more impressive ‘profile’ of publishing?”. There is far to much of that, to satisfy the demands of managers.
Of course it’s right to say that you can get a hint about reliability from the journal in which a paper appears. But you are also right to notice that it’s a pretty imperfect criterion. The fact that the number of citations that a paper gets is independent of the impact factor of the journal in which it appears shows just how imperfect the journal is as a criterion. The only reliable way to judge is to read the paper (but that presupposes knowledge of the area).
Your suggestion is very like one of the options I favour.
“an open source, cloud based, peer reviewed journal, as a multi-institiution and public project. A Journapedia that students wouldn’t be failed for referencing.”
David: it’s really hard to de-identify medical records properly. If you remove postcode, for example, you lose deprivation index. If you don’t allow successive care episodes to be linked, you lose most of the useful epidemiological information; but if you do allow linking then you allow me to ask questions about the public part of your history that identify the private part too. Differentiating between these two parts algorithmically is too hard. More at the URLs I quoted.
Helen: now that citation indices are used for tenure, promotion and funding decisions, publishing has become intrinsically adversarial. Whatever you try to design, people will game it. It’s just like web search; coming top in the Google ranking for “digital camera” is worth millions, so people will do whatever they can to come top. Then Google’s engineers will try to defeat whatever they did, and so on forever. Welcome to the treadmill!
[…] also enjoyed an interesting blog on science funding in hard times, and one on Open Access, as well as papers on improving algal photosynthesis and on making models […]
[…] also enjoyed an interesting blog on science funding in hard times, and one on Open Access, as well as papers on improving algal photosynthesis and on making models […]
Thanks a lot for this post.
While a lot of (more experienced) people have probably thought a lot about it, I am wondering why a few simple suggestions coudn’t be applied quite quickly.
As a first step towards hosting non-reviewed papers on one’s own website, couldn’t we already provide unedited versions of published papers on our websites?
I think (but might be wrong) we retain this right from many publishers…
Moreover, as a way to put some pressure on publishers of “peer-reviewed” articles (and possibly limit the number of useless journals), coudn’t we ask for some kind of payment for reviewing articles ? Of course, I don’t mean receiving money for personal expenses, but a contribution to the research performed by the reviewer would be more than welcome. Why not reduced fees for journal access at the reviewer’s host institute ?
[…] jQuery("#errors*").hide(); window.location= data.themeInternalUrl; } }); } http://www.dcscience.net – December 19, 1:59 […]
[…] jQuery("#errors*").hide(); window.location= data.themeInternalUrl; } }); } http://www.dcscience.net – Today, 6:32 […]
I agree with everything in this article, except the claim that “you have to pay quite a lot” to publish in open-access journals. On the contrary, there are many open-access journals that are free for authors and readers. Here are 10 such journals, just in my area of research:
Electronic J. Combinatorics
J. Computational Geometry
New York J. Mathematics
Documenta Mathematica
Discrete Maths. & Theoretical Comput. Sci.
J. Graph Algorithms & Applications
Contributions to Discrete Mathematics
Theory of Computing
Ars Mathematica Contemporanea
INTEGERS
All of these journals maintain high academic standards.
@David Wood
Thanks for that information. They are not journals that I’d normally read. Presumably they manage to be free to authors because the editors themselves send out papers to referees. Journals like Nature Communications pay an editor and staff to do those jobs, though I rather doubt whether that really costs $5000 per paper.
If you can do it in mathematics, I don’t see why it can’t be done in other sciences too. It’s time that we tried.
[…] a lot of time (numerous attempts) to the process is necessary in order to get success. This applies even if all applications for a given round are equally good. The scale of the effect is quite stark, which may surprise some people. But this paper suggests […]
An important update has just been published by Tim Gowers (see follow-up, above). He reports a lot of progress in penetrating the machinations of publishers, especially Elsevier) that they use to try to maintain their extortionate profits in a publishing world that has changed entirely.
[…] – how much a given institution paid for individual print subscriptions in the 1990s. (Note also an older analysis by UCL’s David Courant that Gowers links to, which shows how the usage of Elsevier journals is high for a few titles but […]