
Download Lectures on Biostatistics (1971). Corrected and searchable version of Google books edition
Download review of Lectures on Biostatistics (THES, 1973).
altmetrics
Chalkdust is a magazine published by students of maths from UCL Mathematics department. Judging by its first issue, it’s an excellent vehicle for popularisation of maths. I have a piece in the second issue
You can view the whole second issue on line, or download a pdf of the whole issue. Or a pdf of my bit only: On the Perils of P values.
The piece started out as another exposition of the interpretation of P values, but the whole of the first part turned into an explanation of the principles of randomisation tests. It beats me why anybody still does a Student’s t test. The idea of randomisation tests is very old. They are as powerful as t tests when the assumptions of the latter are fulfilled but a lot better when the assumptions are wrong (in the jargon, they are uniformly-most-powerful tests).
Not only that, but you need no mathematics to do a randomisation test, whereas you need a good deal of mathematics to follow Student’s 1908 paper. And the randomisation test makes transparently clear that random allocation of treatments is a basic and essential assumption that’s necessary for the the validity of any test of statistical significance.
I made a short video that explains the principles behind the randomisation tests, to go with the printed article (a bit of animation always helps).
When I first came across the principals of randomisation tests, i was entranced by the simplicity of the idea. Chapters 6 – 9 of my old textbook were written to popularise them. You can find much more detail there.
In fact it’s only towards the end that I reiterate the idea that P values don’t answer the question that experimenters want to ask, namely:- if I claim I have made a discovery because P is small, what’s the chance that I’ll be wrong?
If you want the full story on that, read my paper. The story it tells is not very original, but it still isn’t known to most experimenters (because most statisticians still don’t teach it on elementary courses). The paper must have struck a chord because it’s had over 80,000 full text views and more than 10,000 pdf downloads. It reached an altmetric score of 975 (since when it has been mysteriously declining). That’s gratifying, but it is also a condemnation of the use of metrics. The paper is not original and it’s quite simple, yet it’s had far more "impact" than anything to do with my real work.
If you want simpler versions than the full paper, try this blog (part 1 and part 2), or the Youtube video about misinterpretation of P values.
The R code for doing 2-sample randomisation tests
You can download a pdf file that describes the two R scripts. There are two different R programs.
One re-samples randomly a specified number of times (the default is 100,000 times, but you can do any number). Download two_sample_rantest.R
The other uses every possible sample -in the case of the two samples of 10 observations,it gives the distribution for all 184,756 ways of selecting 10 observations from 20. Download 2-sample-rantest-exact.R
The launch party
Today the people who organise Chalkdust magazine held a party in the mathematics department at UCL. The editorial director is a graduate student in maths, Rafael Prieto Curiel. He was, at one time in the Mexican police force (he said he’d suffered more crime in London than in Mexico City). He, and the rest of the team, are deeply impressive. They’ve done a terrific job. Support them.

The party cakes

Rafael Prieto doing the introduction

Rafael Prieto doing the introduction

Rafael Prieto and me

I got the T shirt
Decoding the T shirt
The top line is "I" because that’s the usual symbol for the square root of -1.
|
The second line is one of many equations that describe a heart shape. It can be plotted by calculating a matrix of values of the left hand side for a range of values of x and y. Then plot the contour for a values x and y for which the left hand side is equal to 1. Download R script for this. (Method suggested by Rafael Prieto Curiel.) |
 |
Follow-up
5 November 2015
The Mann-Whitney test
I was stimulated to write this follow-up because yesterday I was asked by a friend to comment on the fact that five different tests all gave identical P values, P = 0.0079. The paper in question was in Science magazine (see Fig. 1), so it wouldn’t surprise me if the statistics were done badly, but in this case there is an innocent explanation.
The Chalkdust article, and the video, are about randomisation tests done using the original observed numbers, so look at them before reading on. There is a more detailed explanation in Chapter 9 of Lectures on Biostatistics. Before it became feasible to do this sort of test, there was a simpler, and less efficient, version in which the observations were ranked in ascending order, and the observed values were replaced by their ranks. This was known as the Mann Whitney test. It had the virtue that because all the ‘observations’ were now integers, the number of possible results of resampling was limited so it was possible to construct tables to allow one to get a rough P value. Of course, replacing observations by their ranks throws away some information, and now that we have computers there is no need to use a Mann-Whitney test ever. But that’s what was used in this paper.
In the paper (Fig 1) comparisons are made between two groups (assumed to be independent) with 5 observations in each group. The 10 observations are just the ranks, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10.
To do the randomisation test we select 5 of these numbers at random for sample A, and the other 5 are sample B. (Of course this supposes that the treatments were applied randomly in the real experiment, which is unlikely to be true.) In fact there are only 10!/(5!.5!) = 252 possible ways to select a sample of 5 from 10, so it’s easy to list all of them. In the case where there is no overlap between the groups, one group will contain the smallest observations (ranks 1, 2, 3, 4, 5, and the other group will contain the highest observations, ranks 6, 7, 8, 9, 10.
In this case, the sum of the ‘observations’ in group A is 15, and the sum for group B is 40.These add to the sum of the first 10 integers, 10.(10+1)/2 = 55. The mean (which corresponds to a difference between means of zero) is 55/2 = 27.5.
There are two ways of getting an allocation as extreme as this (first group low, as above, or second group low, the other tail of the distribution). The two tailed P value is therefore 2/252 = 0.0079. This will be the result whenever the two groups don’t overlap, regardless of the numerical values of the observations. It’s the smallest P value the test can produce with 5 observations in each group.
The whole randomisation distribution looks like this

In this case, the abscissa is the sum of the ranks in sample A, rather than the difference between means for the two groups (the latter is easily calculated from the former). The red line shows the observed value, 15. There is only one way to get a total of 15 for group A: it must contain the lowest 5 ranks (group A = 1, 2, 3, 4, 5). There is also only one way to get a total of 16 (group A = 1, 2, 3, 4, 6),and there are two ways of getting a total of 17 (group A = 1, 2, 3, 4, 7, or 1, 2, 3, 5, 6), But there are 20 different ways of getting a sum of 27 or 28 (which straddle the mean, 27.5). The printout (.txt file) from the R program that was used to generate the distribution is as follows.
|
Randomisation test: exact calculation all possible samples INPUTS: exact calculation: all possible samples OUTPUTS Result of t test
|
Some problems. Figure 1 alone shows 16 two-sample comparisons, but no correction for multiple comparisons seems to have been made. A crude Bonferroni correction would require replacement of a P = 0.05 threshold with P = 0.05/16 = 0.003. None of the 5 tests that gave P = 0.0079 reaches this level (of course the whole idea of a threshold level is absurd anyway).
Furthermore, even a single test that gave P = 0.0079 would be expected to have a false positive rate of around 10 percent
This is very quick synopsis of the 500 pages of a report on the use of metrics in the assessment of research. It’s by far the most thorough bit of work I’ve seen on the topic. It was written by a group, chaired by James Wilsdon, to investigate the possible role of metrics in the assessment of research.
The report starts with a bang. The foreword says
|
"Too often, poorly designed evaluation criteria are “dominating minds, distorting behaviour and determining careers.”1 At their worst, metrics can contribute to what Rowan Williams, the former Archbishop of Canterbury, calls a “new barbarity” in our universities." "The tragic case of Stefan Grimm, whose suicide in September 2014 led Imperial College to launch a review of its use of performance metrics, is a jolting reminder that what’s at stake in these debates is more than just the design of effective management systems." "Metrics hold real power: they are constitutive of values, identities and livelihoods " |
And the conclusions (page 12 and Chapter 9.5) are clear that metrics alone can measure neither the quality of research, nor its impact.
"no set of numbers,however broad, is likely to be able to capture the multifaceted and nuanced judgements on the quality of research outputs that the REF process currently provides"
"Similarly, for the impact component of the REF, it is not currently feasible to use quantitative indicators in place of narrative impact case studies, or the impact template"
These conclusions are justified in great detail in 179 pages of the main report, 200 pages of the literature review, and 87 pages of Correlation analysis of REF2014 scores and metrics
The correlation analysis shows clearly that, contrary to some earlier reports, all of the many metrics that are considered predict the outcome of the 2014 REF far too poorly to be used as a substitute for reading the papers.
There is the inevitable bit of talk about the "judicious" use of metrics tp support peer review (with no guidance about what judicious use means in real life) but this doesn’t detract much from an excellent and thorough job.
Needless to say, I like these conclusions since they are quite similar to those recommended in my submission to the report committee, over a year ago.
Of course peer review is itself fallible. Every year about 8 million researchers publish 2.5 million articles in 28,000 peer-reviewed English language journals (STM report 2015 and graphic, here). It’s pretty obvious that there are not nearly enough people to review carefully such vast outputs. That’s why I’ve said that any paper, however bad, can now be printed in a journal that claims to be peer-reviewed. Nonetheless, nobody has come up with a better system, so we are stuck with it.
It’s certainly possible to judge that some papers are bad. It’s possible, if you have enough expertise, to guess whether or not the conclusions are justified. But no method exists that can judge what the importance of a paper will be in 10 or 20 year’s time. I’d like to have seen a frank admission of that.
If the purpose of research assessment is to single out papers that will be considered important in the future, that job is essentially impossible. From that point of view, the cost of research assessment could be reduced to zero by trusting people to appoint the best people they can find, and just give the same amount of money to each of them. I’m willing to bet that the outcome would be little different. Departments have every incentive to pick good people, and scientists’ vanity is quite sufficient motive for them to do their best.
Such a radical proposal wasn’t even considered in the report, which is a pity. Perhaps they were just being realistic about what’s possible in the present climate of managerialism.
Other recommendations include
"HEIs should consider signing up to the San Francisco Declaration on Research Assessment (DORA)"
4. "Journal-level metrics, such as the Journal Impact Factor (JIF), should not be used."
It’s astonishing that it should be still necessary to deplore the JIF almost 20 years after it was totally discredited. Yet it still mesmerizes many scientists. I guess that shows just how stupid scientists can be outside their own specialist fields.
DORA has over 570 organisational and 12,300 individual signatories, BUT only three universities in the UK have signed (Sussex, UCL and Manchester). That’s a shocking indictment of the way (all the other) universities are run.
One of the signatories of DORA is the Royal Society.
"The RS makes limited use of research metrics in its work. In its publishing activities, ever since it signed DORA, the RS has removed the JIF from its journal home pages and marketing materials, and no longer uses them as part of its publishing strategy. As authors still frequently ask about JIFs, however, the RS does provide them, but only as one of a number of metrics".
That’s a start. I’ve advocated making it a condition to get any grant or fellowship, that the university should have signed up to DORA and Athena Swan (with checks to make sure they are actually obeyed).
And that leads on naturally to one of the most novel and appealing recommendations in the report.
|
"A blog will be set up at http://www.ResponsibleMetrics.org "every year we will award a “Bad Metric” prize to the most |
This should be really interesting. Perhaps I should open a book for which university is the first to win "Bad Metric" prize.
The report covers just about every aspect of research assessment: perverse incentives, whether to include author self-citations, normalisation of citation impact indicators across fields and what to do about the order of authors on multi-author papers.
It’s concluded that there are no satisfactory ways of doing any of these things. Those conclusions are sometimes couched in diplomatic language which may, uh, reduce their impact, but they are clear enough.
The perverse incentives that are imposed by university rankings are considered too. They are commercial products and if universities simply ignored them, they’d vanish. One important problem with rankings is that they never come with any assessment of their errors. It’s been known how to do this at least since Goldstein & Spiegelhalter (1996, League Tables and Their Limitations: Statistical Issues in Comparisons Institutional Performance). Commercial producers of rankings don’t do it, because to do so would reduce the totally spurious impression of precision in the numbers they sell. Vice-chancellors might bully staff less if they knew that the changes they produce are mere random errors.
Metrics, and still more altmetrics, are far too crude to measure the quality of science. To hope to do that without reading the paper is pie in the sky (even reading it, it’s often impossible to tell).
The only bit of the report that I’m not entirely happy about is the recommendation to spend more money investigating the metrics that the report has just debunked. It seems to me that there will never be a way of measuring the quality of work without reading it. To spend money on a futile search for new metrics would take money away from science itself. I’m not convinced that it would be money well-spent.
Follow-up
The Higher Education Funding Council England (HEFCE) gives money to universities. The allocation that a university gets depends strongly on the periodical assessments of the quality of their research. Enormous amounts if time, energy and money go into preparing submissions for these assessments, and the assessment procedure distorts the behaviour of universities in ways that are undesirable. In the last assessment, four papers were submitted by each principal investigator, and the papers were read.
In an effort to reduce the cost of the operation, HEFCE has been asked to reconsider the use of metrics to measure the performance of academics. The committee that is doing this job has asked for submissions from any interested person, by June 20th.
This post is a draft for my submission. I’m publishing it here for comments before producing a final version for submission.
Draft submission to HEFCE concerning the use of metrics.
I’ll consider a number of different metrics that have been proposed for the assessment of the quality of an academic’s work.
Impact factors
The first thing to note is that HEFCE is one of the original signatories of DORA (http://am.ascb.org/dora/ ). The first recommendation of that document is
:"Do not use journal-based metrics, such as Journal Impact Factors, as a surrogate measure of the quality of individual research articles, to assess an individual scientist’s contributions, or in hiring, promotion, or funding decisions"
.Impact factors have been found, time after time, to be utterly inadequate as a way of assessing individuals, e.g. [1], [2]. Even their inventor, Eugene Garfield, says that. There should be no need to rehearse yet again the details. If HEFCE were to allow their use, they would have to withdraw from the DORA agreement, and I presume they would not wish to do this.
Article citations
Citation counting has several problems. Most of them apply equally to the H-index.
- Citations may be high because a paper is good and useful. They equally may be high because the paper is bad. No commercial supplier makes any distinction between these possibilities. It would not be in their commercial interests to spend time on that, but it’s critical for the person who is being judged. For example, Andrew Wakefield’s notorious 1998 paper, which gave a huge boost to the anti-vaccine movement had had 758 citations by 2012 (it was subsequently shown to be fraudulent).
- Citations take far too long to appear to be a useful way to judge recent work, as is needed for judging grant applications or promotions. This is especially damaging to young researchers, and to people (particularly women) who have taken a career break. The counts also don’t take into account citation half-life. A paper that’s still being cited 20 years after it was written clearly had influence, but that takes 20 years to discover,
- The citation rate is very field-dependent. Very mathematical papers are much less likely to be cited, especially by biologists, than more qualitative papers. For example, the solution of the missed event problem in single ion channel analysis [3,4] was the sine qua non for all our subsequent experimental work, but the two papers have only about a tenth of the number of citations of subsequent work that depended on them.
- Most suppliers of citation statistics don’t count citations of books or book chapters. This is bad for me because my only work with over 1000 citations is my 105 page chapter on methods for the analysis of single ion channels [5], which contained quite a lot of original work. It has had 1273 citations according to Google scholar but doesn’t appear at all in Scopus or Web of Science. Neither do the 954 citations of my statistics text book [6]
- There are often big differences between the numbers of citations reported by different commercial suppliers. Even for papers (as opposed to book articles) there can be a two-fold difference between the number of citations reported by Scopus, Web of Science and Google Scholar. The raw data are unreliable and commercial suppliers of metrics are apparently not willing to put in the work to ensure that their products are consistent or complete.
- Citation counts can be (and already are being) manipulated. The easiest way to get a large number of citations is to do no original research at all, but to write reviews in popular areas. Another good way to have ‘impact’ is to write indecisive papers about nutritional epidemiology. That is not behaviour that should command respect.
- Some branches of science are already facing something of a crisis in reproducibility [7]. One reason for this is the perverse incentives which are imposed on scientists. These perverse incentives include the assessment of their work by crude numerical indices.
- “Gaming” of citations is easy. (If students do it it’s called cheating: if academics do it is called gaming.) If HEFCE makes money dependent on citations, then this sort of cheating is likely to take place on an industrial scale. Of course that should not happen, but it would (disguised, no doubt, by some ingenious bureaucratic euphemisms).
- For example, Scigen is a program that generates spoof papers in computer science, by stringing together plausible phases. Over 100 such papers have been accepted for publication. By submitting many such papers, the authors managed to fool Google Scholar in to awarding the fictitious author an H-index greater than that of Albert Einstein http://en.wikipedia.org/wiki/SCIgen
- The use of citation counts has already encouraged guest authorships and such like marginally honest behaviour. There is no way to tell with an author on a paper has actually made any substantial contribution to the work, despite the fact that some journals ask for a statement about contribution.
- It has been known for 17 years that citation counts for individual papers are not detectably correlated with the impact factor of the journal in which the paper appears [1]. That doesn’t seem to have deterred metrics enthusiasts from using both. It should have done.
Given all these problems, it’s hard to see how citation counts could be useful to the REF, except perhaps in really extreme cases such as papers that get next to no citations over 5 or 10 years.
The H-index
This has all the disadvantages of citation counting, but in addition it is strongly biased against young scientists, and against women. This makes it not worth consideration by HEFCE.
Altmetrics
Given the role given to “impact” in the REF, the fact that altmetrics claim to measure impact might make them seem worthy of consideration at first sight. One problem is that the REF failed to make a clear distinction between impact on other scientists is the field and impact on the public.
Altmetrics measures an undefined mixture of both sorts if impact, with totally arbitrary weighting for tweets, Facebook mentions and so on. But the score seems to be related primarily to the trendiness of the title of the paper. Any paper about diet and health, however poor, is guaranteed to feature well on Twitter, as will any paper that has ‘penis’ in the title.
It’s very clear from the examples that I’ve looked at that few people who tweet about a paper have read more than the title. See Why you should ignore altmetrics and other bibliometric nightmares [8].
In most cases, papers were promoted by retweeting the press release or tweet from the journal itself. Only too often the press release is hyped-up. Metrics not only corrupt the behaviour of academics, but also the behaviour of journals. In the cases I’ve examined, reading the papers revealed that they were particularly poor (despite being in glamour journals): they just had trendy titles [8].
There could even be a negative correlation between the number of tweets and the quality of the work. Those who sell altmetrics have never examined this critical question because they ignore the contents of the papers. It would not be in their commercial interests to test their claims if the result was to show a negative correlation. Perhaps the reason why they have never tested their claims is the fear that to do so would reduce their income.
Furthermore you can buy 1000 retweets for $8.00 http://followers-and-likes.com/twitter/buy-twitter-retweets/ That’s outright cheating of course, and not many people would go that far. But authors, and journals, can do a lot of self-promotion on twitter that is totally unrelated to the quality of the work.
It’s worth noting that much good engagement with the public now appears on blogs that are written by scientists themselves, but the 3.6 million views of my blog do not feature in altmetrics scores, never mind Scopus or Web of Science. Altmetrics don’t even measure public engagement very well, never mind academic merit.
Evidence that metrics measure quality
Any metric would be acceptable only if it measured the quality of a person’s work. How could that proposition be tested? In order to judge this, one would have to take a random sample of papers, and look at their metrics 10 or 20 years after publication. The scores would have to be compared with the consensus view of experts in the field. Even then one would have to be careful about the choice of experts (in fields like alternative medicine for example, it would be important to exclude people whose living depended on believing in it). I don’t believe that proper tests have ever been done (and it isn’t in the interests of those who sell metrics to do it).
The great mistake made by almost all bibliometricians is that they ignore what matters most, the contents of papers. They try to make inferences from correlations of metric scores with other, equally dubious, measures of merit. They can’t afford the time to do the right experiment if only because it would harm their own “productivity”.
The evidence that metrics do what’s claimed for them is almost non-existent. For example, in six of the ten years leading up to the 1991 Nobel prize, Bert Sakmann failed to meet the metrics-based publication target set by Imperial College London, and these failures included the years in which the original single channel paper was published [9] and also the year, 1985, when he published a paper [10] that was subsequently named as a classic in the field [11]. In two of these ten years he had no publications whatsoever. See also [12].
Application of metrics in the way that it’s been done at Imperial and also at Queen Mary College London, would result in firing of the most original minds.
Gaming and the public perception of science
Every form of metric alters behaviour, in such a way that it becomes useless for its stated purpose. This is already well-known in economics, where it’s know as Goodharts’s law http://en.wikipedia.org/wiki/Goodhart’s_law “"When a measure becomes a target, it ceases to be a good measure”. That alone is a sufficient reason not to extend metrics to science. Metrics have already become one of several perverse incentives that control scientists’ behaviour. They have encouraged gaming, hype, guest authorships and, increasingly, outright fraud [13].
The general public has become aware of this behaviour and it is starting to do serious harm to perceptions of all science. As long ago as 1999, Haerlin & Parr [14] wrote in Nature, under the title How to restore Public Trust in Science,
“Scientists are no longer perceived exclusively as guardians of objective truth, but also as smart promoters of their own interests in a media-driven marketplace.”
And in January 17, 2006, a vicious spoof on a Science paper appeared, not in a scientific journal, but in the New York Times. See https://www.dcscience.net/?p=156

The use of metrics would provide a direct incentive to this sort of behaviour. It would be a tragedy not only for people who are misjudged by crude numerical indices, but also a tragedy for the reputation of science as a whole.
Conclusion
There is no good evidence that any metric measures quality, at least over the short time span that’s needed for them to be useful for giving grants or deciding on promotions). On the other hand there is good evidence that use of metrics provides a strong incentive to bad behaviour, both by scientists and by journals. They have already started to damage the public perception of science of the honesty of science.
The conclusion is obvious. Metrics should not be used to judge academic performance.
What should be done?
If metrics aren’t used, how should assessment be done? Roderick Floud was president of Universities UK from 2001 to 2003. He’s is nothing if not an establishment person. He said recently:
“Each assessment costs somewhere between £20 million and £100 million, yet 75 per cent of the funding goes every time to the top 25 universities. Moreover, the share that each receives has hardly changed during the past 20 years.
It is an expensive charade. Far better to distribute all of the money through the research councils in a properly competitive system.”
The obvious danger of giving all the money to the Research Councils is that people might be fired solely because they didn’t have big enough grants. That’s serious -it’s already happened at Kings College London, Queen Mary London and at Imperial College. This problem might be ameliorated if there were a maximum on the size of grants and/or on the number of papers a person could publish, as I suggested at the open data debate. And it would help if univerities appointed vice-chancellors with a better long term view than most seem to have at the moment.
Aggregate metrics? It’s been suggested that the problems are smaller if one looks at aggregated metrics for a whole department. rather than the metrics for individual people. Clearly looking at departments would average out anomalies. The snag is that it wouldn’t circumvent Goodhart’s law. If the money depended on the aggregate score, it would still put great pressure on universities to recruit people with high citations, regardless of the quality of their work, just as it would if individuals were being assessed. That would weigh against thoughtful people (and not least women).
The best solution would be to abolish the REF and give the money to research councils, with precautions to prevent people being fired because their research wasn’t expensive enough. If politicians insist that the "expensive charade" is to be repeated, then I see no option but to continue with a system that’s similar to the present one: that would waste money and distract us from our job.
1. Seglen PO (1997) Why the impact factor of journals should not be used for evaluating research. British Medical Journal 314: 498-502. [Download pdf]
2. Colquhoun D (2003) Challenging the tyranny of impact factors. Nature 423: 479. [Download pdf]
3. Hawkes AG, Jalali A, Colquhoun D (1990) The distributions of the apparent open times and shut times in a single channel record when brief events can not be detected. Philosophical Transactions of the Royal Society London A 332: 511-538. [Get pdf]
4. Hawkes AG, Jalali A, Colquhoun D (1992) Asymptotic distributions of apparent open times and shut times in a single channel record allowing for the omission of brief events. Philosophical Transactions of the Royal Society London B 337: 383-404. [Get pdf]
5. Colquhoun D, Sigworth FJ (1995) Fitting and statistical analysis of single-channel records. In: Sakmann B, Neher E, editors. Single Channel Recording. New York: Plenum Press. pp. 483-587.
6. David Colquhoun on Google Scholar. Available: http://scholar.google.co.uk/citations?user=JXQ2kXoAAAAJ&hl=en17-6-2014
7. Ioannidis JP (2005) Why most published research findings are false. PLoS Med 2: e124.[full text]
8. Colquhoun D, Plested AJ Why you should ignore altmetrics and other bibliometric nightmares. Available: https://www.dcscience.net/?p=6369
9. Neher E, Sakmann B (1976) Single channel currents recorded from membrane of denervated frog muscle fibres. Nature 260: 799-802.
10. Colquhoun D, Sakmann B (1985) Fast events in single-channel currents activated by acetylcholine and its analogues at the frog muscle end-plate. J Physiol (Lond) 369: 501-557. [Download pdf]
11. Colquhoun D (2007) What have we learned from single ion channels? J Physiol 581: 425-427.[Download pdf]
12. Colquhoun D (2007) How to get good science. Physiology News 69: 12-14. [Download pdf] See also https://www.dcscience.net/?p=182
13. Oransky, I. Retraction Watch. Available: http://retractionwatch.com/18-6-2014
14. Haerlin B, Parr D (1999) How to restore public trust in science. Nature 400: 499. 10.1038/22867 [doi].[Get pdf]
Follow-up
Some other posts on this topic
Why Metrics Cannot Measure Research Quality: A Response to the HEFCE Consultation
Gaming Google Scholar Citations, Made Simple and Easy
Manipulating Google Scholar Citations and Google Scholar Metrics: simple, easy and tempting
Driving Altmetrics Performance Through Marketing
Death by Metrics (October 30, 2013)
Not everything that counts can be counted
Using metrics to assess research quality By David Spiegelhalter “I am strongly against the suggestion that peer–review can in any way be replaced by bibliometrics”
1 July 2014
My brilliant statistical colleague, Alan Hawkes, not only laid the foundations for single molecule analysis (and made a career for me) . Before he got into that, he wrote a paper, Spectra of some self-exciting and mutually exciting point processes, (Biometrika 1971). In that paper he described a sort of stochastic process now known as a Hawkes process. In the simplest sort of stochastic process, the Poisson process, events are independent of each other. In a Hawkes process, the occurrence of an event affects the probability of another event occurring, so, for example, events may occur in clusters. Such processes were used for many years to describe the occurrence of earthquakes. More recently, it’s been noticed that such models are useful in finance, marketing, terrorism, burglary, social media, DNA analysis, and to describe invasive banana trees. The 1971 paper languished in relative obscurity for 30 years. Now the citation rate has shot threw the roof.

The papers about Hawkes processes are mostly highly mathematical. They are not the sort of thing that features on twitter. They are serious science, not just another ghastly epidemiological survey of diet and health. Anybody who cites papers of this sort is likely to be a real scientist. The surge in citations suggests to me that the 1971 paper was indeed an important bit of work (because the citations will be made by serious people). How does this affect my views about the use of citations? It shows that even highly mathematical work can achieve respectable citation rates, but it may take a long time before their importance is realised. If Hawkes had been judged by citation counting while he was applying for jobs and promotions, he’d probably have been fired. If his department had been judged by citations of this paper, it would not have scored well. It takes a long time to judge the importance of a paper and that makes citation counting almost useless for decisions about funding and promotion.
This discussion seemed to be of sufficient general interest that we submitted is as a feature to eLife, because this journal is one of the best steps into the future of scientific publishing. Sadly the features editor thought that " too much of the article is taken up with detailed criticisms of research papers from NEJM and Science that appeared in the altmetrics top 100 for 2013; while many of these criticisms seems valid, the Features section of eLife is not the venue where they should be published". That’s pretty typical of what most journals would say. It is that sort of attitude that stifles criticism, and that is part of the problem. We should be encouraging post-publication peer review, not suppressing it. Luckily, thanks to the web, we are now much less constrained by journal editors than we used to be.
Here it is.
Scientists don’t count: why you should ignore altmetrics and other bibliometric nightmares
David Colquhoun1 and Andrew Plested2
1 University College London, Gower Street, London WC1E 6BT
2 Leibniz-Institut für Molekulare Pharmakologie (FMP) & Cluster of Excellence NeuroCure, Charité Universitätsmedizin,Timoféeff-Ressowsky-Haus, Robert-Rössle-Str. 10, 13125 Berlin Germany.
Jeffrey Beall is librarian at Auraria Library, University of Colorado Denver. Although not a scientist himself, he, more than anyone, has done science a great service by listing the predatory journals that have sprung up in the wake of pressure for open access. In August 2012 he published “Article-Level Metrics: An Ill-Conceived and Meretricious Idea. At first reading that criticism seemed a bit strong. On mature consideration, it understates the potential that bibliometrics, altmetrics especially, have to undermine both science and scientists.
Altmetrics is the latest buzzword in the vocabulary of bibliometricians. It attempts to measure the “impact” of a piece of research by counting the number of times that it’s mentioned in tweets, Facebook pages, blogs, YouTube and news media. That sounds childish, and it is. Twitter is an excellent tool for journalism. It’s good for debunking bad science, and for spreading links, but too brief for serious discussions. It’s rarely useful for real science.
Surveys suggest that the great majority of scientists do not use twitter (7 — 13%). Scientific works get tweeted about mostly because they have titles that contain buzzwords, not because they represent great science.
What and who is Altmetrics for?
The aims of altmetrics are ambiguous to the point of dishonesty; they depend on whether the salesperson is talking to a scientist or to a potential buyer of their wares.
At a meeting in London , an employee of altmetric.com said “we measure online attention surrounding journal articles” “we are not measuring quality …” “this whole altmetrics data service was born as a service for publishers”, “it doesn’t matter if you got 1000 tweets . . .all you need is one blog post that indicates that someone got some value from that paper”.
These ideas sound fairly harmless, but in stark contrast, Jason Priem (an author of the altmetrics manifesto) said one advantage of altmetrics is that it’s fast “Speed: months or weeks, not years: faster evaluations for tenure/hiring”. Although conceivably useful for disseminating preliminary results, such speed isn’t important for serious science (the kind that ought to be considered for tenure) which operates on the timescale of years. Priem also says “researchers must ask if altmetrics really reflect impact” . Even he doesn’t know, yet altmetrics services are being sold to universities, before any evaluation of their usefulness has been done, and universities are buying them. The idea that altmetrics scores could be used for hiring is nothing short of terrifying.
The problem with bibliometrics
The mistake made by all bibliometricians is that they fail to consider the content of papers, because they have no desire to understand research. Bibliometrics are for people who aren’t prepared to take the time (or lack the mental capacity) to evaluate research by reading about it, or in the case of software or databases, by using them. The use of surrogate outcomes in clinical trials is rightly condemned. Bibliometrics are all about surrogate outcomes.
If instead we consider the work described in particular papers that most people agree to be important (or that everyone agrees to be bad), it’s immediately obvious that no publication metrics can measure quality. There are some examples in How to get good science (Colquhoun, 2007). It is shown there that at least one Nobel prize winner failed dismally to fulfil arbitrary biblometric productivity criteria of the sort imposed in some universities (another example is in Is Queen Mary University of London trying to commit scientific suicide?).
Schekman (2013) has said that science
“is disfigured by inappropriate incentives. The prevailing structures of personal reputation and career advancement mean the biggest rewards often follow the flashiest work, not the best.”
Bibliometrics reinforce those inappropriate incentives. A few examples will show that altmetrics are one of the silliest metrics so far proposed.
The altmetrics top 100 for 2103
The superficiality of altmetrics is demonstrated beautifully by the list of the 100 papers with the highest altmetric scores in 2013 For a start, 58 of the 100 were behind paywalls, and so unlikely to have been read except (perhaps) by academics.
The second most popular paper (with the enormous altmetric score of 2230) was published in the New England Journal of Medicine. The title was Primary Prevention of Cardiovascular Disease with a Mediterranean Diet. It was promoted (inaccurately) by the journal with the following tweet:

Many of the 2092 tweets related to this article simply gave the title, but inevitably the theme appealed to diet faddists, with plenty of tweets like the following:


The interpretations of the paper promoted by these tweets were mostly desperately inaccurate. Diet studies are anyway notoriously unreliable. As John Ioannidis has said
"Almost every single nutrient imaginable has peer reviewed publications associating it with almost any outcome."
This sad situation comes about partly because most of the data comes from non-randomised cohort studies that tell you nothing about causality, and also because the effects of diet on health seem to be quite small.
The study in question was a randomized controlled trial, so it should be free of the problems of cohort studies. But very few tweeters showed any sign of having read the paper. When you read it you find that the story isn’t so simple. Many of the problems are pointed out in the online comments that follow the paper. Post-publication peer review really can work, but you have to read the paper. The conclusions are pretty conclusively demolished in the comments, such as:
“I’m surrounded by olive groves here in Australia and love the hand-pressed EVOO [extra virgin olive oil], which I can buy at a local produce market BUT this study shows that I won’t live a minute longer, and it won’t prevent a heart attack.”
We found no tweets that mentioned the finding from the paper that the diets had no detectable effect on myocardial infarction, death from cardiovascular causes, or death from any cause. The only difference was in the number of people who had strokes, and that showed a very unimpressive P = 0.04.
Neither did we see any tweets that mentioned the truly impressive list of conflicts of interest of the authors, which ran to an astonishing 419 words.
“Dr. Estruch reports serving on the board of and receiving lecture fees from the Research Foundation on Wine and Nutrition (FIVIN); serving on the boards of the Beer and Health Foundation and the European Foundation for Alcohol Research (ERAB); receiving lecture fees from Cerveceros de España and Sanofi-Aventis; and receiving grant support through his institution from Novartis. Dr. Ros reports serving on the board of and receiving travel support, as well as grant support through his institution, from the California Walnut Commission; serving on the board of the Flora Foundation (Unilever). . . “
And so on, for another 328 words.
The interesting question is how such a paper came to be published in the hugely prestigious New England Journal of Medicine. That it happened is yet another reason to distrust impact factors. It seems to be another sign that glamour journals are more concerned with trendiness than quality.
One sign of that is the fact that the journal’s own tweet misrepresented the work. The irresponsible spin in this initial tweet from the journal started the ball rolling, and after this point, the content of the paper itself became irrelevant. The altmetrics score is utterly disconnected from the science reported in the paper: it more closely reflects wishful thinking and confirmation bias.
The fourth paper in the altmetrics top 100 is an equally instructive example.
|
This work was also published in a glamour journal, Science. The paper claimed that a function of sleep was to “clear metabolic waste from the brain”. It was initially promoted (inaccurately) on Twitter by the publisher of Science. After that, the paper was retweeted many times, presumably because everybody sleeps, and perhaps because the title hinted at the trendy, but fraudulent, idea of “detox”. Many tweets were variants of “The garbage truck that clears metabolic waste from the brain works best when you’re asleep”. |
|
But this paper was hidden behind Science’s paywall. It’s bordering on irresponsible for journals to promote on social media papers that can’t be read freely. It’s unlikely that anyone outside academia had read it, and therefore few of the tweeters had any idea of the actual content, or the way the research was done. Nevertheless it got “1,479 tweets from 1,355 accounts with an upper bound of 1,110,974 combined followers”. It had the huge Altmetrics score of 1848, the highest altmetric score in October 2013.
Within a couple of days, the story fell out of the news cycle. It was not a bad paper, but neither was it a huge breakthrough. It didn’t show that naturally-produced metabolites were cleared more quickly, just that injected substances were cleared faster when the mice were asleep or anaesthetised. This finding might or might not have physiological consequences for mice.
Worse, the paper also claimed that “Administration of adrenergic antagonists induced an increase in CSF tracer influx, resulting in rates of CSF tracer influx that were more comparable with influx observed during sleep or anesthesia than in the awake state”. Simply put, giving the sleeping mice a drug could reduce the clearance to wakeful levels. But nobody seemed to notice the absurd concentrations of antagonists that were used in these experiments: “adrenergic receptor antagonists (prazosin, atipamezole, and propranolol, each 2 mM) were then slowly infused via the cisterna magna cannula for 15 min”. Use of such high concentrations is asking for non-specific effects. The binding constant (concentration to occupy half the receptors) for prazosin is less than 1 nM, so infusing 2 mM is working at a million times greater than the concentration that should be effective. That’s asking for non-specific effects. Most drugs at this sort of concentration have local anaesthetic effects, so perhaps it isn’t surprising that the effects resembled those of ketamine.
The altmetrics editor hadn’t noticed the problems and none of them featured in the online buzz. That’s partly because to find it out you had to read the paper (the antagonist concentrations were hidden in the legend of Figure 4), and partly because you needed to know the binding constant for prazosin to see this warning sign.
The lesson, as usual, is that if you want to know about the quality of a paper, you have to read it. Commenting on a paper without knowing anything of its content is liable to make you look like an jackass.
A tale of two papers
Another approach that looks at individual papers is to compare some of one’s own papers. Sadly, UCL shows altmetric scores on each of your own papers. Mostly they are question marks, because nothing published before 2011 is scored. But two recent papers make an interesting contrast. One is from DC’s side interest in quackery, one was real science. The former has an altmetric score of 169, the latter has an altmetric score of 2.
|
The first paper was “Acupuncture is a theatrical placebo”, which was published as an invited editorial in Anesthesia and Analgesia [download pdf]. The paper was scientifically trivial. It took perhaps a week to write. Nevertheless, it got promoted it on twitter, because anything to do with alternative medicine is interesting to the public. It got quite a lot of retweets. And the resulting altmetric score of 169 put it in the top 1% of all articles altmetric have tracked, and the second highest ever for Anesthesia and Analgesia. As well as the journal’s own website, the article was also posted on the DCScience.net blog (May 30, 2013) where it soon became the most viewed page ever (24,468 views as of 23 November 2013), something that altmetrics does not seem to take into account. |

|
Compare this with the fate of some real, but rather technical, science.
|
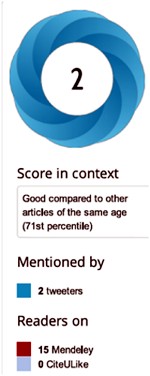
My [DC] best scientific papers are too old (i.e. before 2011) to have an altmetrics score, but my best score for any scientific paper is 2. This score was for Colquhoun & Lape (2012) “Allosteric coupling in ligand-gated ion channels”. It was a commentary with some original material. The altmetric score was based on two tweets and 15 readers on Mendeley. The two tweets consisted of one from me (“Real science; The meaning of allosteric conformation changes http://t.co/zZeNtLdU ”). The only other tweet as abusive one from a cyberstalker who was upset at having been refused a job years ago. Incredibly, this modest achievement got it rated “Good compared to other articles of the same age (71st percentile)”. |
|
Conclusions about bibliometrics
Bibliometricians spend much time correlating one surrogate outcome with another, from which they learn little. What they don’t do is take the time to examine individual papers. Doing that makes it obvious that most metrics, and especially altmetrics, are indeed an ill-conceived and meretricious idea. Universities should know better than to subscribe to them.
Although altmetrics may be the silliest bibliometric idea yet, much this criticism applies equally to all such metrics. Even the most plausible metric, counting citations, is easily shown to be nonsense by simply considering individual papers. All you have to do is choose some papers that are universally agreed to be good, and some that are bad, and see how metrics fail to distinguish between them. This is something that bibliometricians fail to do (perhaps because they don’t know enough science to tell which is which). Some examples are given by Colquhoun (2007) (more complete version at dcscience.net).
Eugene Garfield, who started the metrics mania with the journal impact factor (JIF), was clear that it was not suitable as a measure of the worth of individuals. He has been ignored and the JIF has come to dominate the lives of researchers, despite decades of evidence of the harm it does (e.g.Seglen (1997) and Colquhoun (2003) ) In the wake of JIF, young, bright people have been encouraged to develop yet more spurious metrics (of which ‘altmetrics’ is the latest). It doesn’t matter much whether these metrics are based on nonsense (like counting hashtags) or rely on counting links or comments on a journal website. They won’t (and can’t) indicate what is important about a piece of research- its quality.
People say – I can’t be a polymath. Well, then don’t try to be. You don’t have to have an opinion on things that you don’t understand. The number of people who really do have to have an overview, of the kind that altmetrics might purport to give, those who have to make funding decisions about work that they are not intimately familiar with, is quite small. Chances are, you are not one of them. We review plenty of papers and grants. But it’s not credible to accept assignments outside of your field, and then rely on metrics to assess the quality of the scientific work or the proposal.
It’s perfectly reasonable to give credit for all forms of research outputs, not only papers. That doesn’t need metrics. It’s nonsense to suggest that altmetrics are needed because research outputs are not already valued in grant and job applications. If you write a grant for almost any agency, you can put your CV. If you have a non-publication based output, you can always include it. Metrics are not needed. If you write software, get the numbers of downloads. Software normally garners citations anyway if it’s of any use to the greater community.
When AP recently wrote a criticism of Heather Piwowar’s altmetrics note in Nature, one correspondent wrote: "I haven’t read the piece [by HP] but I’m sure you are mischaracterising it". This attitude summarizes the too-long-didn’t-read (TLDR) culture that is increasingly becoming accepted amongst scientists, and which the comparisons above show is a central component of altmetrics.
Altmetrics are numbers generated by people who don’t understand research, for people who don’t understand research. People who read papers and understand research just don’t need them and should shun them.
But all bibliometrics give cause for concern, beyond their lack of utility. They do active harm to science. They encourage “gaming” (a euphemism for cheating). They encourage short-term eye-catching research of questionable quality and reproducibility. They encourage guest authorships: that is, they encourage people to claim credit for work which isn’t theirs. At worst, they encourage fraud.
No doubt metrics have played some part in the crisis of irreproducibility that has engulfed some fields, particularly experimental psychology, genomics and cancer research. Underpowered studies with a high false-positive rate may get you promoted, but tend to mislead both other scientists and the public (who in general pay for the work). The waste of public money that must result from following up badly done work that can’t be reproduced but that was published for the sake of “getting something out” has not been quantified, but must be considered to the detriment of bibliometrics, and sadly overcomes any advantages from rapid dissemination. Yet universities continue to pay publishers to provide these measures, which do nothing but harm. And the general public has noticed.
It’s now eight years since the New York Times brought to the attention of the public that some scientists engage in puffery, cheating and even fraud.
Overblown press releases written by journals, with connivance of university PR wonks and with the connivance of the authors, sometimes go viral on social media (and so score well on altmetrics). Yet another example, from Journal of the American Medical Association involved an overblown press release from the Journal about a trial that allegedly showed a benefit of high doses of Vitamin E for Alzheimer’s disease.
This sort of puffery harms patients and harms science itself.
We can’t go on like this.
What should be done?
Post publication peer review is now happening, in comments on published papers and through sites like PubPeer, where it is already clear that anonymous peer review can work really well. New journals like eLife have open comments after each paper, though authors do not seem to have yet got into the habit of using them constructively. They will.
It’s very obvious that too many papers are being published, and that anything, however bad, can be published in a journal that claims to be peer reviewed . To a large extent this is just another example of the harm done to science by metrics –the publish or perish culture.
Attempts to regulate science by setting “productivity targets” is doomed to do as much harm to science as it has in the National Health Service in the UK. This has been known to economists for a long time, under the name of Goodhart’s law.
Here are some ideas about how we could restore the confidence of both scientists and of the public in the integrity of published work.
- Nature, Science, and other vanity journals should become news magazines only. Their glamour value distorts science and encourages dishonesty.
- Print journals are overpriced and outdated. They are no longer needed. Publishing on the web is cheap, and it allows open access and post-publication peer review. Every paper should be followed by an open comments section, with anonymity allowed. The old publishers should go the same way as the handloom weavers. Their time has passed.
- Web publication allows proper explanation of methods, without the page, word and figure limits that distort papers in vanity journals. This would also make it very easy to publish negative work, thus reducing publication bias, a major problem (not least for clinical trials)
- Publish or perish has proved counterproductive. It seems just as likely that better science will result without any performance management at all. All that’s needed is peer review of grant applications.
- Providing more small grants rather than fewer big ones should help to reduce the pressure to publish which distorts the literature. The ‘celebrity scientist’, running a huge group funded by giant grants has not worked well. It’s led to poor mentoring, and, at worst, fraud. Of course huge groups sometimes produce good work, but too often at the price of exploitation of junior scientists
- There is a good case for limiting the number of original papers that an individual can publish per year, and/or total funding. Fewer but more complete and considered papers would benefit everyone, and counteract the flood of literature that has led to superficiality.
- Everyone should read, learn and inwardly digest Peter Lawrence’s The Mismeasurement of Science.
A focus on speed and brevity (cited as major advantages of altmetrics) will help no-one in the end. And a focus on creating and curating new metrics will simply skew science in yet another unsatisfactory way, and rob scientists of the time they need to do their real job: generate new knowledge.
It has been said
“Creation is sloppy; discovery is messy; exploration is dangerous. What’s a manager to do?
The answer in general is to encourage curiosity and accept failure. Lots of failure.”
And, one might add, forget metrics. All of them.
Follow-up
17 Jan 2014
This piece was noticed by the Economist. Their ‘Writing worth reading‘ section said
"Why you should ignore altmetrics (David Colquhoun) Altmetrics attempt to rank scientific papers by their popularity on social media. David Colquohoun [sic] argues that they are “for people who aren’t prepared to take the time (or lack the mental capacity) to evaluate research by reading about it.”"
20 January 2014.
Jason Priem, of ImpactStory, has responded to this article on his own blog. In Altmetrics: A Bibliographic Nightmare? he seems to back off a lot from his earlier claim (cited above) that altmetrics are useful for making decisions about hiring or tenure. Our response is on his blog.
20 January 2014.
Jason Priem, of ImpactStory, has responded to this article on his own blog, In Altmetrics: A bibliographic Nightmare? he seems to back off a lot from his earlier claim (cited above) that altmetrics are useful for making decisions about hiring or tenure. Our response is on his blog.
23 January 2014
The Scholarly Kitchen blog carried another paean to metrics, A vigorous discussion followed. The general line that I’ve followed in this discussion, and those mentioned below, is that bibliometricians won’t qualify as scientists until they test their methods, i.e. show that they predict something useful. In order to do that, they’ll have to consider individual papers (as we do above). At present, articles by bibliometricians consist largely of hubris, with little emphasis on the potential to cause corruption. They remind me of articles by homeopaths: their aim is to sell a product (sometimes for cash, but mainly to promote the authors’ usefulness).
It’s noticeable that all of the pro-metrics articles cited here have been written by bibliometricians. None have been written by scientists.
28 January 2014.
Dalmeet Singh Chawla,a bibliometrician from Imperial College London, wrote a blog on the topic. (Imperial, at least in its Medicine department, is notorious for abuse of metrics.)
29 January 2014 Arran Frood wrote a sensible article about the metrics row in Euroscientist.
2 February 2014 Paul Groth (a co-author of the Altmetrics Manifesto) posted more hubristic stuff about altmetrics on Slideshare. A vigorous discussion followed.
5 May 2014. Another vigorous discussion on ImpactStory blog, this time with Stacy Konkiel. She’s another non-scientist trying to tell scientists what to do. The evidence that she produced for the usefulness of altmetrics seemed pathetic to me.
7 May 2014 A much-shortened version of this post appeared in the British Medical Journal (BMJ blogs)
[This an update of a 2006 post on my old blog]
The New York Times (17 January 2006) published a beautiful spoof that illustrates only too clearly some of the bad practices that have developed in real science (as well as in quackery). It shows that competition, when taken to excess, leads to dishonesty.
More to the point, it shows that the public is well aware of the dishonesty that has resulted from the publish or perish culture, which has been inflicted on science by numbskull senior administrators (many of them scientists, or at least ex-scientists). Part of the blame must attach to "bibliometricians" who have armed administrators with simple-minded tools the usefulness is entirely unverified. Bibliometricians are truly the quacks of academia. They care little about evidence as long as they can sell the product.
The spoof also illustrates the folly of allowing the hegemony of a handful of glamour journals to hold scientists in thrall. This self-inflicted wound adds to the pressure to produce trendy novelties rather than solid long term work.
It also shows the only-too-frequent failure of peer review to detect problems.
The future lies on publication on the web, with post-publication peer review. It has been shown by sites like PubPeer that anonymous post-publication review can work very well indeed. This would be far cheaper, and a good deal better than the present extortion practised on universities by publishers. All it needs is for a few more eminent people like mathematician Tim Gowers to speak out (see Elsevier – my part in its downfall).
Recent Nobel-prizewinner Randy Schekman has helped with his recent declaration that "his lab will no longer send papers to Nature, Cell and Science as they distort scientific process"
The spoof is based on the fraudulent papers by Korean cloner, Woo Suk Hwang, which were published in Science, in 2005. As well as the original fraud, this sad episode exposed the practice of ‘guest authorship’, putting your name on a paper when you have done little or no work, and cannot vouch for the results. The last (‘senior’) author on the 2005 paper, was Gerald Schatten, Director of the Pittsburgh Development Center. It turns out that Schatten had not seen any of the original data and had contributed very little to the paper, beyond lobbying Scienceto accept it. A University of Pittsburgh panel declared Schatten guilty of “research misbehavior”, though he was, amazingly, exonerated of “research misconduct”. He still has his job. Click here for an interesting commentary.
The New York Times carried a mock editorial to introduce the spoof..

One Last Question: Who Did the Work? By NICHOLAS WADE In the wake of the two fraudulent articles on embryonic stem cells published in Science by the South Korean researcher Hwang Woo Suk, Donald Kennedy, the journal’s editor, said last week that he would consider adding new requirements that authors “detail their specific contributions to the research submitted,” and sign statements that they agree with the conclusions of their article. A statement of authors’ contributions has long been championed by Drummond Rennie, deputy editor of The Journal of the American Medical Association, Explicit statements about the conclusions could bring to light many reservations that individual authors would not otherwise think worth mentioning. The article shown [below] from a future issue of the Journal of imaginary Genomics, annotated in the manner required by Science‘s proposed reforms, has been released ahead of its embargo date. |
The old-fashioned typography makes it obvious that the spoof is intended to mock a paper in Science.

The problem with this spoof is its only too accurate description of what can happen at the worst end of science.
Something must be done if we are to justify the money we get and and we are to retain the confidence of the public
My suggestions are as follows
- Nature Science and Cell should become news magazines only. Their glamour value distorts science and encourages dishonesty
- All print journals are outdated. We need cheap publishing on the web, with open access and post-publication peer review. The old publishers would go the same way as the handloom weavers. Their time has past.
- Publish or perish has proved counterproductive. You’d get better science if you didn’t have any performance management at all. All that’s needed is peer review of grant applications.
- It’s better to have many small grants than fewer big ones. The ‘celebrity scientist’, running a huge group funded by many grants has not worked well. It’s led to poor mentoring and exploitation of junior scientists.
- There is a good case for limiting the number of original papers that an individual can publish per year, and/or total grant funding. Fewer but more complete papers would benefit everyone.
- Everyone should read, learn and inwardly digest Peter Lawrence’s The Mismeasurement of Science.
Follow-up
3 January 2014.
Yet another good example of hype was in the news. “Effect of Vitamin E and Memantine on Functional Decline in Alzheimer Disease“. It was published in the Journal of the American Medical Association. The study hit the newspapers on January 1st with headlines like Vitamin E may slow Alzheimer’s Disease (see the excellent analyis by Gary Schwitzer). The supplement industry was ecstatic. But the paper was behind a paywall. It’s unlikely that many of the tweeters (or journalists) had actually read it.
The trial was a well-designed randomised controlled trial that compared four treatments: placebo, vitamin E, memantine and Vitamin E + memantine.
Reading the paper gives a rather different impression from the press release. Look at the pre-specified primary outcome of the trial.
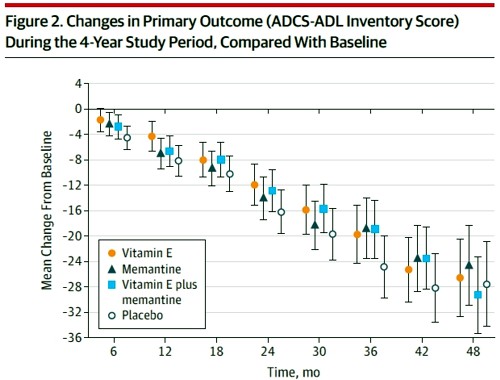
The primary outcome measure was
" . . the Alzheimer’s Disease Cooperative Study/Activities of Daily Living (ADCSADL) Inventory.12 The ADCS-ADL Inventory is designed to assess functional abilities to perform activities of daily living in Alzheimer patients with a broad range of dementia severity. The total score ranges from 0 to 78 with lower scores indicating worse function."
It looks as though any difference that might exist between the four treaments is trivial in size. In fact the mean difference between Vitamin E and placebos was only 3.15 (on a 78 point scale) with 95% confidence limits from 0.9 to 5.4. This gave a modest P = 0.03 (when properly corrected for multiple comparisons), a result that will impress only those people who regard P = 0.05 as a sort of magic number. Since the mean effect is so trivial in size that it doesn’t really matter if the effect is real anyway.
It is not mentioned in the coverage that none of the four secondary outcomes achieved even a modest P = 0.05 There was no detectable effect of Vitamin E on
- Mean annual rate of cognitive decline (Alzheimer Disease Assessment Scale–Cognitive Subscale)
- Mean annual rate of cognitive decline (Mini-Mental State Examination)
- Mean annual rate of increased symptoms
- Mean annual rate of increased caregiver time,
The only graph that appeared to show much effect was The Dependence Scale. This scale
“assesses 6 levels of functional dependence. Time to event is the time to loss of 1 dependence level (increase in dependence). We used an interval-censored model assuming a Weibull distribution because the time of the event was known only at the end of a discrete interval of time (every 6 months).”
It’s presented as a survival (Kaplan-Meier) plot. And it is this somewhat obscure secondary outcome that was used by the Journal of the American Medical Assocciation for its publicity.
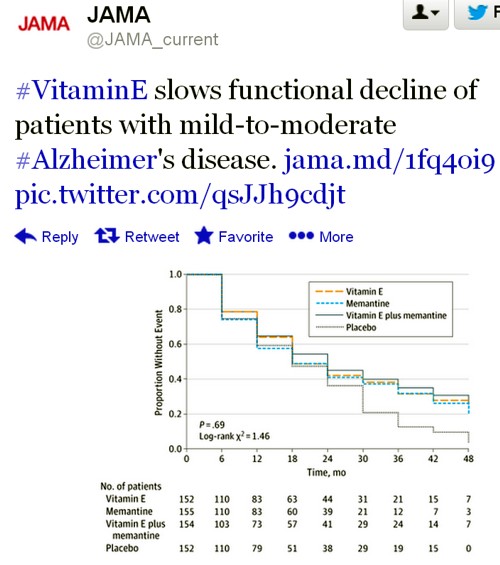
Note also that memantine + Vitamin E was indistinguishable from placebo. There are two ways to explain this: either Vitamin E has no effect, or memantine is an antagonist of Vitamin E. There are no data on the latter, but it’s certainly implausible.
The trial used a high dose of Vitamin E (2000 IU/day). No toxic effects of Vitamin E were reported, though a 2005 meta-analysis concluded that doses greater than 400 IU/d "may increase all-cause mortality and should be avoided".
In my opinion, the outcome of this trial should have been something like “Vitamin E has, at most, trivial effects on the progress of Alzheimer’s disease”.
Both the journal and the authors are guilty of disgraceful hype. This continual raising of false hopes does nothing to help patients. But it does damage the reputation of the journal and of the authors.
|
This paper constitutes yet another failure of altmetrics. (see more examples on this blog). Not surprisingly, given the title, It was retweeted widely, but utterly uncritically. Bad science was promoted. And JAMA must take much of the blame for publishing it and promoting it. |
|